| Каталог документации / Раздел "Сети, протоколы, сервисы" / Оглавление документа |
| |
|
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
4 Сети передачи данных. Методы доступа
Семенов Ю.А. (ГНЦ ИТЭФ) |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Топология Среди топологических схем наиболее популярными являются (см. рис. 4.1):
Рис. 4.1. Примеры сетевых топологий К первым трем типам топологии относятся 99% всех локальных сетей. Наиболее популярный тип сети - Ethernet, может строиться по схемам 1 и 2. Вариант 1 наиболее дешев, так как требует по одному интерфейсу на машину и не нуждается в каком-либо дополнительном оборудовании. Сети Token Ring и FDDI используют кольцевую топологию (3 на рис. 4.1), где каждый узел должен иметь два сетевых интерфейса. Эта топология удобна для оптоволоконных каналов, где сигнал может передаваться только в одном направлении (но при наличии двух колец, как в FDDI, возможна и двунаправленная передача). Нетрудно видеть, что кольцевая топология строится из последовательности соединений точка-точка. Используется и немалое количество других топологий, которые являются комбинациями уже названных. Примеры таких топологий представлены на рис. 4.2. Вариант А на рис. 4.2 представляет собой схему с полным набором связей (все узлы соединены со всеми), такая схема используется только в случае, когда необходимо обеспечить высокую надежность соединений. Эта версия требует для каждого из узлов наличия n-1 интерфейсов при полном числе узлов n. Вариант Б является примером нерегулярной топологии, а вариант В - иерархический случай связи (древовидная топология). Если топологии на рис. 4.1 чаще применимы для локальных сетей, то топологии на рис. 4.2 более типичны для региональных и глобальных сетей. Выбор топологии локальной или региональной сети существенно сказывается на ее стоимости и рабочих характеристиках. При этом важной характеристикой при однородной сети является среднее число шагов между узлами d.
Рис. 4.2. Различные сетевые топологические схемы Современные вычислительные системы используют и другие топологии: решетки (А), кубы (В), гипердеревья (Б), гиперкубы и т.д. (см. рис. 4.3). Но так как некоторые вычислительные системы (кластеры) базируются на сетевых технологиях, я привожу и такие примеры. В некоторых системах топология может настраиваться на решаемую задачу.
Рис. 4.3. Некоторые топологии вычислительных систем Метод доступа к сети Метод доступа определяет метод, который используется при мультиплексировании/демультиплексировании данных в процессе передачи их по сети. Большая часть современных сетей базируется на алгоритме доступа CSMA/CD (carrier sensitive multiple access with collision detection), где все узлы имеют равные возможности доступа к сетевой среде, а при одновременной попытке фиксируется столкновение и сеанс передачи повторяется позднее. Здесь нет возможности приоритетного доступа и по этой причине такие сети плохо приспособлены для задач управления в реальном масштабе времени. Некоторое видоизменение алгоритма CSMA/CD (как это сделано в сетях CAN или в IBM DSDB) позволяют преодолеть эти ограничения. Доступ по схеме CSMA/CD (из-за столкновений) предполагает ограничение на минимальную длину пакета. По существу, метод доступа CSMA/CD предполагает широковещательную передачу пакетов (не путать с широковещательной адресацией). Все рабочие станции логического сетевого сегмента воспринимают эти пакеты хотя бы частично, чтобы прочесть адресную часть. При широковещательной адресации пакеты не только считываются целиком в буфер, но и производится прерывание процессора для обработки факта прихода такого пакета. Логика поведения субъектов в сети с доступом CSMA/CD может варьироваться. Здесь существенную роль играет то, синхронизовано ли время доступа у этих субъектов. В случае Ethernet такой синхронизации нет. В общем случае при наличии синхронизации возможны следующие алгоритмы. А.
Алгоритм А на первый взгляд представляется привлекательным, но в нем заложена возможность столкновений с вероятностью 100%. Алгоритмы Б и В более устойчивы в отношении этой проблемы. Следующим по популярности после csma/cd является маркерный доступ (Token Ring, Arcnet и FDDI), который более гибок и обеспечивает приоритетную иерархию обслуживания. Массовому его внедрению препятствует сложность и дороговизна. Хотя региональные сети имеют самую разнообразную топологию, практически всегда они строятся на связях точка-точка. В таблице 4.1 представлены сводные данные по основным видам локальных сетей, используемых в настоящее время (список не является полным). Таблица 4.1. Параметры различных локальных сетей
Приведенная таблица не может претендовать на полноту. Так сюда не вошла сеть IBM DSDB, разработанная в начале 80-х годов. Полоса пропускания сети составляет 64 Мбит/с. Эта сеть рассчитана на обслуживания процессов реального времени. Сеть имеет топологию шины с приоритетным доступом (длина шины до 500м). Коммуникационная шина логически делится на три магистрали: сигнальная - для реализации приоритетного доступа; лексемная шина для резервирования в буфере места назначения; и, наконец, коммуникационная шина для передачи данных. Каждая из указанных магистралей использует идеологию независимых временных доменов, границы которых синхронизованы для всех трех магистралей. Схема доступа сходна с описанной для сетей CAN (см. раздел 4.1.4).
Данная схема доступа исключает столкновения, характерные для CSMA. Именно это преимущество делает сеть применимой для задач реального времени. Существует целое семейство методов доступа, исключающих столкновение: это мультиплексирование по времени (TDM) и по частоте (FDM). Здесь каждому клиенту выделяется определенный временной домен или частотный диапазон. Когда наступает его временной интервал и клиент имеет кадр (или бит), предназначенный для отправки, он делает это. При этом каждый клиент ждет в среднем n/2 временных интервалов (предполагается, что работает n клиентов). При FDM передача не требует ожидания. Но в обоих случаях временные интервалы или частотные диапазоны используются клиентом по мере необходимости и могут заметное время быть не заняты (простаивать). Такие протоколы доступа часто используются в мобильной связи. Интересной разновидностью Ethernet является широкополосная сеть типа Net/one. Она может базироваться на коаксиальном кабеле (суммарная длина до 1500м) или на оптическом волокне (полная длина до 2500м). Эта сеть по многим характеристикам аналогична обычному ethernet (CSMA/CD) за исключением того, что коммуникационное оборудование передает данные на одной частоте, а принимает - на другой. Для каждого канала выделяется полоса 5 Мбит/с (полоса пропускания 6МГц соответствует телевизионному стандарту). Предусматривается 5 передающих (59,75-89,75 МГц) и 5 принимающих (252-282 МГц) каналов для каждого из сетевых сегментов. Частота ошибок (BER) для сети данного типа меньше 10-8. Другой Ethernet-совместимой сетью является Fibercom Whispernet. Сеть имеет кольцевую структуру (до 8км), полосу пропускания 10Мбит/c, число узлов до 100 на сегменте при полном числе узлов в сети - 1024. Число кольцевых сегментов может достигать 101. Максимальное межузловое расстояние - 2км. Примером нетрадиционного типа сети может служить Localnet 20 (Sytek). Сеть базируется на одном коаксиальном кабеле и имеет полную полосу пропускания 400 МГц. Сеть делится на 120 каналов, каждый из которых работает со скоростью 128 Кбит/с. Каналы используют две 36МГц-полосы, одна для передачи, другая для приема. Каждый из коммуникационных каналов занимает 300КГц из 36МГц. Сеть использует алгоритм доступа CSMA/CD, что позволяет подключать к одному каналу большое число сетевых устройств. Предусматривается совместимость с интерфейсом RS-232. Частота ошибок в сети не более 10-8. Фирма Дженерал Электрик разработала сеть gm (map-шина), совместимую со стандартом IEEE 802.4. Целью разработки было обеспечение совместимости с производственным оборудованием различных компаний. Сеть рассчитана на работу со скоростями 1, 5 и 50 Мбит/с. Традиционные сети и телекоммуникационные каналы образуют основу сети - ее физический уровень. Реальная топология сети может динамически изменяться, хотя это и происходит обычно незаметно для участников. При реализации сети используются десятки протоколов. В любых коммуникационных протоколах важное значение имеют операции, ориентированные на установление связи (connection-oriented) и операции, не требующие связи (connectionless - "бессвязные", ISO 8473). Интернет использует оба типа операций. При первом типе пользователь и сеть сначала устанавливают логическую связь и только затем начинают обмен данными. Причем между отдельными пересылаемыми блоками данных (пакетами) поддерживается некоторое взаимодействие. "Бессвязные" операции не предполагают установления какой-либо связи между пользователем и сетью (например, протокол UDP) до начала обмена. Отдельные блоки передаваемых данных в этом случае абсолютно независимы и не требуют подтверждения получения. Пакеты могут быть потеряны, задублированы или доставлены не в порядке их отправки, причем ни отправитель, ни получатель не будут об этом оповещены. Именно к этому типу относится базовый протокол Интернет - IP. Для каждой сети характерен свой интервал размеров пакетов. Среди факторов, влияющих на выбор размеров можно выделить
Ниже приведены максимальные размеры пакетов (mtu) для ряда сетей
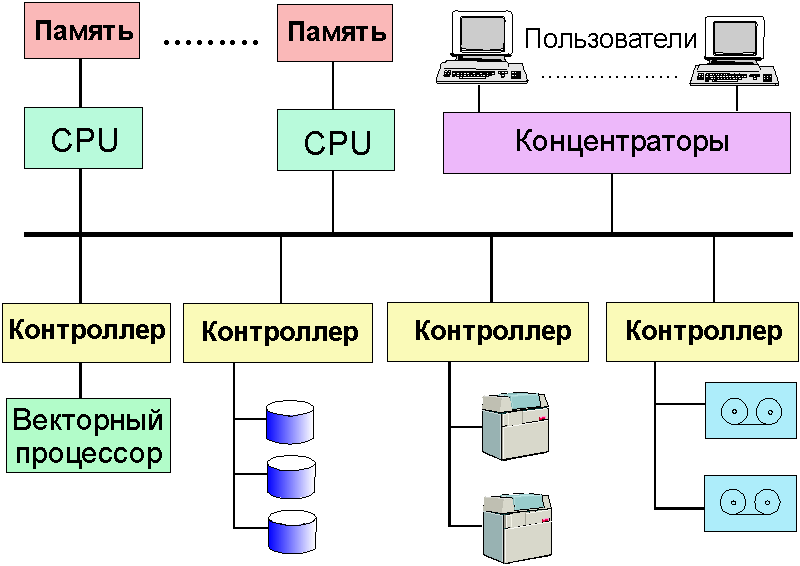
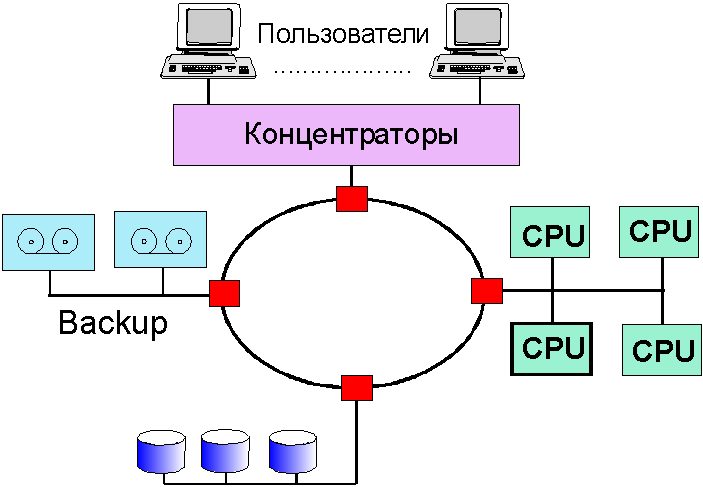
Операции, ориентированные на установление связи (например, протокол TCP), предполагают трехстороннее соглашение между двумя пользователями и провайдером услуг. В процессе обмена они хранят необходимую информацию друг о друге, с тем, чтобы не перегружать вспомогательными данными пересылаемые пакеты. В этом режиме обмена обычно требуется подтверждение получения пакета, а при обнаружении сбоя предусматривается механизм повторной передачи поврежденного пакета. "Бессвязная" сеть более надежна, так как она может отправлять отдельные пакеты по разным маршрутам, обходя поврежденные участки. Такая сеть не зависит от протоколов, используемых в субсетях. Большинство протоколов Интернет используют именно эту схему обмена. Концептуально TCP/IP-сети предлагают три типа сервиса в порядке нарастания уровня иерархии: Немногие из читателей участвуют в создании региональных и тем более глобальных сетей, за то структура и принципы построения локальных сетей им, безусловно, близки. На рис. 4.4 и 4.5 приведены два варианта "ресурсных" локальных сетей (сети для коллективного использования ресурсов - памяти, процессоров, принтеров, магнитофонов и т.д.). Такие сети строятся так, чтобы пропускная способность участков, где информационные потоки суммируются, имели адекватную полосу пропускания. Эффективность сети на рис. 4.4 сильно зависит от структуры и возможностей контроллеров внешних устройств, от объема их буферной памяти.
Рис. 4.4. Вариант схемы ресурсной локальной сети Сеть, показанная на рис. 4.5, несравненно более эффективна (практически исключены столкновения и легче гарантировать определенное время доступа к ресурсу). Здесь также немало зависит от свойств контроллеров внешних ресурсов (помечены красным цветом). Но такие сети обычно более дорого реализовать.
Рис. 4.5. Для сопоставления быстродействия различных видов сетей Сталлингс (Stallings, W.: Data and Computer Communications, New York: Mac-Millan Publishing Company, 1985) в 1985 году разработал критерий. Критерий предполагает вычисление битовой длины BL (максимальное число бит в сегменте), которая равна произведению максимальной длины сегмента (L) на полосу пропускания (W), деленное на скорость распространения сигнала в сегменте (S): BL = l*W/S Для Ethernet BL = [500(м)*10 106(бит/c)]/2 108 (м/c) = 25 бит. Коэффициент использования сети равен b = 1/(1+a), где
Принципы построения сетевых программных интерфейсов Существует большое разнообразие сетевых интерфейсов. Их структура зависит от характера физического уровня сетевой среды, от метода доступа, от используемого набора интегральных схем и т.д.. Здесь пойдет речь о принципах построения программного интерфейса (см. также раздел 7; ..\7\soft_7.html). Существует три возможности построения интерфейса: с базированием на памяти, с использованием прямого доступа и с применением запросов обслуживания. Первый вариант предполагает наличие трех компонентов: буфер сообщений, область данных для управления передачей и зона памяти для управления приемом данных. Первый из компонентов служит для формирования исходящих сообщений программного интерфейса. Должны быть приняты меры, чтобы исключить модификацию содержимого этого буфера до того, как данные будут считаны ЭВМ или интерфейсом. Проблема решается путем формирования соответствующих указателей. Управление буфером осуществляется ЭВМ или совместно ЭВМ и интерфейсом с использованием механизма семафоров. Остальные методы связаны с использованием традиционных методов управления памятью с помощью средств операционной системы. Критической проблемой является обеспечение достаточного места в буфере для приходящих сообщений. Ведь в отсутствии памяти приходящее или записанное ранее сообщение может быть потеряно. Недостаток места для исходящих сообщений не является критическим, так как приводит обычно к задержке передачи, а не к потере сообщения. Второй компонент интерфейса, базирующегося на использовании памяти, часто реализуется в виде так называемых буферов управления передачей (TCB). Эти буферы содержат такую информацию как положения сообщения в памяти, длина сообщения, адрес места назначения, идентификатор процесса-отправителя, приоритет сообщения, предельное значение числа попыток передачи, а также флаг, указывающий на необходимость присылки подтверждения от получателя. TCB (transmission control buffer) создается процессом-отправителем и передается интерфейсу, после завершения записи в буфер сообщений. Параметры TCB используются интерфейсом при организации процесса передачи сообщения. Третий компонент интерфейса, базирующегося на использовании памяти, называется буфером управления приемом (RCB - Reception Control Buffer). RCB содержит в себе информацию, сходную с той, что записывается в TCB, например, идентификатор отправителя, длина сообщения, индикатор ошибки, время приема и идентификатор процесса места назначения. RCB заполняется интерфейсом при получении сообщения и передается процессору ЭВМ. Основополагающим принципом построение всех трех компонент является совместное использование памяти и гибкая система указателей. Версия программы, рассмотренная в разделе 7 ближе именно к этой схеме взаимодействия. Во втором варианте широко используемой схемы доступа к сети ("прямой доступ") взаимодействие ЭВМ и интерфейса строится по схеме клиент-сервер. Конкретная реализация программы в этом случае в большей степени зависит от структуры регистров физического интерфейса. В третьем варианте сетевого программного интерфейса используются служебные запросы. Этот тип сетевого доступа удобен для коммуникационных протоколов высокого уровня, таких как команды ввода/вывода CSP-стиля (Communicating Sequential Processes) или процедуры обмена языка Ада. В этом методе накладываются определенные ограничения на реализацию нижележащих коммуникационных уровней. Программирование для сетей существенным образом является программированием для процессов реального времени. Здесь часто можно столкнуться с тем, что одна и та же программа ведет себя по-разному в разных ситуациях. Особое внимание нужно уделять написанию многопроцессных сетевых программ, где также как в случае (см. раздел 7.1; ..\7\sock_71.html) работы с соединителями могут возникать ситуации блокировок. Пример такой ситуации показан на рис. 4.6.
Рис. 4.6. Когда число процессов больше, заметить запрограммированную ситуацию блокировки заметно сложнее. По этой причине необходимо предусмотреть меры препятствующие блокировке, если ожидаемое сообщение не пришло. Необычайно важной проблемой при построении сетей является их устойчивость при возникновении перегрузок. В Интернет для этого используется специальная опция протокола ICMP, а во Frame Relay имеются меры для преодоления перегрузок непосредственно на нижних протокольных уровнях. Оптимальность управления сетью в условиях перегрузок определяет эффективность использования сети. Пока субсеть загружена незначительно, число принимаемых и обрабатываемых пакетов равно числу пришедших. Однако, когда в субсеть поступает слишком много пакетов может возникнуть перегрузка и рабочие характеристики деградируют. При очень больших загрузках пропускная способность канала или сети может стать нулевой (см. [39]) Такая ситуация называется коллапсом сети. Отчасти это может быть связано с недостатком памяти для входных буферов, по этой причине некоторое увеличение памяти может помочь. Но следует помнить, что всякое лекарство хорошо в меру. Еще в 1987 году Нагле (Nagle) обнаружил, что если маршрутизатор имеет даже беспредельную память, эффект перегрузки может оказаться еще более тяжелым. Это сопряжено со временем, которые пакеты ожидают обработки. Если время ожидания в очереди превышает длительность таймаута, появятся дубликаты пакетов, что, безусловно, понижает эффективность системы. Причиной перегрузки может быть медленный процессор или недостаточная пропускная способность какого-то участка сети. Простая замена процессора или интерфейса на более быстродействующий не всегда решает проблему - чаще переносит узкое место в другую часть системы. Перегрузка, как правило, включает механизмы, усиливающие ее негативное воздействие. Так переполнение буфера приводит к потере пакетов, которые позднее должны будут переданы повторно (возможно даже несколько раз). Процессор передающей стороны получает дополнительную паразитную загрузку. Все это указывает на то, что контроль перегрузки является крайне важным процессом. Следует делать различие между контролем потока и контролем перегрузки. Под контролем потока подразумевается балансировка потока отправителя и возможности приема и обработки получателя. Этот вид контроля предполагает наличие обратной связи между получателем и отправителем. В этом процессе участвуют, как правило, только два партнера. Перегрузка же более общее явление, относящееся к сети в целом или к какой-то ее части. Например, 10 ЭВМ хотят передать одновременно какие-то файлы другим 10 ЭВМ. Конфликта потоков здесь нет, каждая из ЭВМ способна переработать поступающие данные, но сеть не может пропустить поток, генерируемый 10 сетевыми интерфейсами одновременно. Часто эти явления не так просто разделить. Отправитель может получить сообщение ICMP (quench) (в случае TCP/IP) при перегрузке получателя или при перегрузке какого-то сегмента сети. Начинать надо с решения проблемы выявления перегрузок. Перегрузкой следует считать ситуацию, когда нагрузка в течение некоторого оговоренного времени превышает заданную величину. Параметрами, которые позволяют судить о наличии перегрузки могут служить: Когда перегрузка выявлена, нужно передать необходимую информацию из точки, где она обнаружена, туда, где можно что-то сделать для исправления ситуации. Можно послать уведомление о перегрузке отправителю, загружая дополнительно и без того перегруженный участок сети. Альтернативой этому может быть применение специального поля в пакете, куда маршрутизатор может записать соответствующий код при перегрузке, и послать его соседям. Можно также ввести специальный процессор или маршрутизатор, который рассылает периодически запросы о состоянии элементов сети. При получении оповещения о перегрузки информационный поток может быть послан в обход. При использовании обратной связи путем посылки сообщения-запроса понижения скорости передачи следует тщательно настраивать временные характеристики. В противном случае система либо попадает в незатухающий осциллятивный режим, либо корректирующее понижение потока будет осуществляться слишком поздно. Для корректного выбора режима обратной связи необходимо некоторое усреднение. Преодоление перегрузки может быть осуществлено понижением нагрузки или добавлением ресурсов приемнику. Положительный результат может быть достигнут изменением механизма подтверждения (например, уменьшением размера окна), вариацией значений таймаутов, вариацией политики повторной передачи пакетов. В некоторых случаях позитивный результат может быть получен изменением схемы буферизации. Иногда решить проблему может маршрутизатор, например, перераспределяющий трафик по нескольким направлениям. Одной из причин перегрузки часто являются импульсные загрузки сегмента сети или сетевого устройства. По этой причине любые меры (напр., pipelining), которые могут выравнять поток пакетов, безусловно улучшат ситуацию (например, traffic shaping в сетях ATM). В TCP же с его окнами импульсные загрузки предопределены. Алгоритм leaky bucket ("дырявое ведро") Для систем без обратной связи решение проблемы выравнивания скорости передачи данных может быть решено с помощью алгоритма leaky bucket. Суть этого алгоритма заключается в том, что на пути потока устанавливается буфер выходной поток которого постоянен и согласован с возможностью приемника. Если буфер переполняется, пакеты теряются. Потеря пакетов вещь мало приятная, но это блокирует процессы, которые могут привести к коллапсу сегмента или всей сети. Там, где потеря пакетов нежелательна, можно применить более гибкий алгоритм. Алгоритм Token Bucket ("маркерное ведро") Алгоритм token bucket предполагает наличие в буферном устройстве (или программе) некоторого количества маркеров. При поступлении на вход буфера пакетов маркеры используются для их транспортировки на выход. Дальнейшая передача данных на выход зависит от генерации новых маркеров. Поступающие извне пакеты тем временем накапливаются в буфере. Таким образом, полной гарантии отсутствия потерь мы не имеем и здесь. Но алгоритм token bucket позволяет передавать на выход "плотные" группы пакетов ограниченной численности (по числу маркеров), снижая в некоторых случаях вероятность потери. Если буферное устройство "смонтировано" внутри ЭВМ-отправителя, потерь можно избежать вовсе, блокируя передачу при заполнении буфера. Как в одном так и в другом алгоритме мерой передаваемой информации может быть не пакет, а n-байт (где n некоторое оговоренное заранее число). В системах, где управление трафиком осуществляется с использованием обратной связи, можно достичь большей эффективности. Одним из механизмов преодоления перегрузок является управление разрешением (admission control). Суть метода заключается в том, что при регистрации перегрузки не формируется более никаких виртуальных соединений до тех пор, пока ситуация не улучшится. Альтернативным вариантом может служить решение, где формирование нового соединения разрешается, но при этом осуществляется маршрутизация так, чтобы обойти узлы, в которых выявлена перегрузка (смотри рис. 4.7 ).
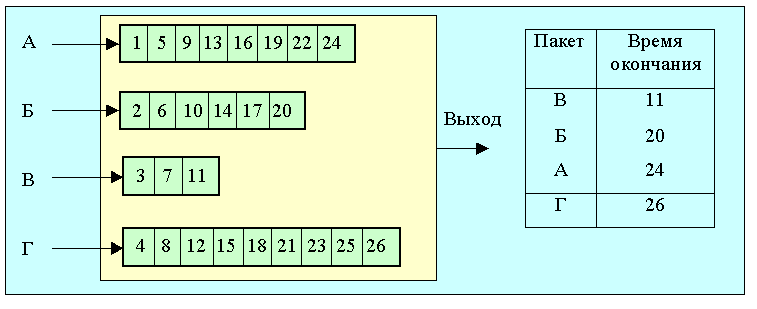
Рис. 4.7. Выбор маршрута нового виртуального канала при наличии перегрузки На рис. 4.7 (верх) показан пример сети с двумя узлами, характеризующимися перегрузкой (помечены красным цветом). Предположим, что необходимо проложить виртуальный канал из узла А в узел Б. Из графа маршрутов удаляются перегруженные узлы, после чего осуществляется прокладка пути. В нижней части рисунка синим цветом показан новый виртуальный канал. Еще более универсальным решение, пригодным для работы с установлением соединения и без, является посылка пакетов блокировки (choke packets). Маршрутизатор обычно контролирует загруженность всех своих внешних каналов l, которая может принимать значения от 0 до 1. Когда l достигает некоторого порогового значения, отправителю посылается пакет блокировки. При вычислении l следует использовать какую-либо методику усреднения, чтобы избежать слишком частых блокировок. Когда отправитель получает пакет блокировки, он должен уменьшить трафик, посылаемый получателю на заданное число процентов. Так как на пути к месту назначения может быть много пакетов, это вызовет серию пакетов блокировки. Отправитель должен игнорировать пакеты блокировки в течение некоторого времени после получения первого такого пакета. По истечении этого периода отправитель прослушивает канал на протяжении аналогичного времени, ожидая получения новых пакетов блокировки. Если такой пакет приходит, канал все еще перегружен и отправитель снова должен понизить темп посылки пакетов. Если на протяжение периода прослушивания не приходит новых пакетов блокировки, отправитель может увеличить поток снова. ЭВМ может понижать трафик, корректируя свои параметры, например, ширину окна или темп передачи на выходе устройства типа "дырявое ведро". Обычно первый блокирующий пакет уменьшает поток вдвое, следующий на 0,25 от первичного и т.д. Увеличение потока также производится аналогичными шагами. Существует большое число вариантов алгоритма управления потоком с использованием пакетов блокировки. Параметром, который контролируется и определяет условие отправки пакета блокировки, может служить длина очереди или заполненность буфера. Ситуация перегрузки не всегда управляется однозначно. Например, при поступлении на вход пакетов от трех источников возможна ситуация, когда приемник посылает блокирующие пакеты всем отправителям, а откликнется сокращением потока только один. В результате этот узел, который "играет по правилам" (как это часто бывает и в жизни) оказывается в проигрыше. В 1987 году Нагле был предложен алгоритм fair queueing (честная очередь). В этом алгоритме маршрутизатор организует независимые очереди для пакетов, поступающих от разных источников. Когда выходной канал маршрутизатора оказывается свободным, он просматривает очереди циклически и отравляет очередной пакет. В результате при n очередях по завершении такого цикла просмотров-посылок оказываются посланы по одному пакету из каждой очереди. Такой алгоритм используется в некоторых ATM-переключателях. Следует заметить, что этот алгоритм дает некоторые преимущества тем узлам, которые посылают более длинные пакеты. Демерс (Demers) и др. в 1990 году предложил некоторое усовершенствоввание алгоритма. В данном варианте организуется циклический просмотр очередей не по-пакетно, а по-байтно. Система последовательно сканирует очереди и определяет положение концов пакетов. Первыми отправляются более короткие пакеты. Для иллюстрации предлагается рассмотреть рис. 4.8. (см. также [39])
Рис. 4.8. Маршрутизатор с 4-мя входными каналами, в каждом из которых ждет очереди передачи по одному пакету. В правой части рисунка представлен порядок посылки этих пакетов. Пакеты на рисунке имеют от трех до девяти октетов. Порядок пересылки октетов показан в левой части рисунка. В отсутствии поступления новых пакетов, кадры, записанные в буфер будут переданы в порядке, представленном в правой части рисунка. Особенностью этого алгоритма является равенство приоритета всех входных каналов. При передаче данных на большие расстояния с большими значениями RTT эффективность использования метода блокирующих пакетов снижается. Пока блокирующий пакет дойдет через ряд промежуточных узлов до отправителя, на вход получателя поступит большое число пакетов, которые не только усугубят ситуацию перегрузки, но и могут вызвать потерю какой-то их доли, что, в свою очередь, может потребовать повторной пересылки следовавших за ними кадров. Для повышения эффективности часто применяется схема, при которой блокирующие пакеты воздействуют на все маршрутизаторы по пути своего следования. В этом случае снижения потока можно ожидать уже чарез время, равное RTT до узла, ближайшего к получателю пакетов. Такая схема требует того, чтобы все промежуточные узлы имели достаточно емкие буферы, в противном случае возможны потери. В протоколе TCP используется алгоритм управления трафиком, называемый "скользящее окно". Здесь размер окна, которое определяет число сегментов, посылаемых без получения подтверждения, варьируется в зависимости от наличия потерь пакетов. При большой вероятности потери система переходит в режим, когда очередной пакет не посылается до тех пор, пока не будет подтверждено получение предшествующего. При серьезных перегрузках, когда потери становятся значительными, нарушается механизм вычисления значений RTT и таймаутов, что может приводить к трудно предсказуемым последствиям. Следует обратить внимание, что в протоколе UDP какого-либо механизма управления трафиком не предусмотрено. По этой причине для некоторых мультимедийных задач, следует предусматривать другие, например, ICMP-способы подавления перегрузки. В приложениях типа NFS, где используется UDP, для подавления перегрузки используется упомянутый выше ICMP-механизм. К сожаления в ряде мультимедийных приложений потеря пакетов не контролируется (например IP-телефония). Там шлюз 100-10Мбит/с может восприниматься как канал с вероятностью потери пакета 90%. Если другие способы испробованы, а перегрузка не исчезла, маршрутизатор начинает отбрасывать приходящие пакеты, которые уже не может обработать. Самое простое - это предоставить случаю выбор отбрасываемых пакетов. Но это не лучшая тактика. В случае пересылки мультимедийных данных предпочтение следует делать для последних полученных пакетов, а "старые" пакеты выбрасывать. При передаче файлов наоборот "старый" пакет имеет приоритет, ведь если его отбросить, придется повторно передавать не только его, но и все последующие пакеты. Некоторые методы передачи изображения требуют передачи время от времени всего кадра с последующей пересылкой только фрагментов, где произошли изменения. В таких условиях потеря пакета, составляющего базовый кадр, менее желательна. Сходные обстоятельства могут возникать и в других приложениях. Можно помечать пакеты, присваивая им определенные уровни приоритетов, что позволит осознанно принимать решение об отбрасывании того или иного пакета в условиях перегрузки. В перспективе проблема может быть решена на чисто коммерческой основе - компонента трафика, помеченная как высоко приоритетная, будет оплачиваться по более высокому тарифу. В некоторых сетях определенное количество пакетов объединяется в группы, образующие сообщение. Если одна ячейка такого сообщения выбрашена, все сообщение будет повторно переслано (смотри, например, адаптационные уровни сетей ATM). |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Previous:
3.6 Протокол G.703
UP:
3 Каналы передачи данных
|



|
Закладки на сайте Проследить за страницей |
Created 1996-2025 by Maxim Chirkov Добавить, Поддержать, Вебмастеру |


 , где nd - число ЭВМ на расстоянии d.
n - полное число ЭВМ в сети; d - расстояние между ЭВМ. Для сети типа А на рис. 4.2 d=1.
, где nd - число ЭВМ на расстоянии d.
n - полное число ЭВМ в сети; d - расстояние между ЭВМ. Для сети типа А на рис. 4.2 d=1.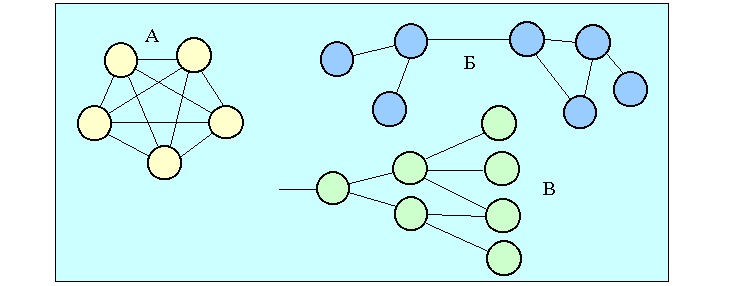

 . Для Ethernet при длине пакета
1500 байта a = 0,0021, что дает для эффективности использования сети 0,997. Таким образом, максимальная пропускная способность ethernet составляет 9,97 Мбит/c или 1,25 Мбайт/с. Разумеется, в этом подходе не учитываются издержки, связанные с заголовками пакетов, которые дополнительно снижают эффективность сети. Из данного рассмотрения может показаться, что
чем больше пакет, тем лучше. С точки зрения пропускной способности так оно и есть. Но с увеличением длины пакета увеличивается время отклика сети. Таким образом, выбор MTU определяется реальными требованиями пользователей.
. Для Ethernet при длине пакета
1500 байта a = 0,0021, что дает для эффективности использования сети 0,997. Таким образом, максимальная пропускная способность ethernet составляет 9,97 Мбит/c или 1,25 Мбайт/с. Разумеется, в этом подходе не учитываются издержки, связанные с заголовками пакетов, которые дополнительно снижают эффективность сети. Из данного рассмотрения может показаться, что
чем больше пакет, тем лучше. С точки зрения пропускной способности так оно и есть. Но с увеличением длины пакета увеличивается время отклика сети. Таким образом, выбор MTU определяется реальными требованиями пользователей.