|
Компания Google открыла исходные тексты платформы ClusterFuzz, предназначенной для проведения fuzzing-тестирования кода с использованием кластера серверов. Кроме координации выполнения проверок ClusterFuzz также автоматизирует выполнение таких задач, как
отправка уведомления разработчикам, создание заявки на исправление (issue), отслеживание исправления ошибки и закрытие отчётов после исправления. Код написан на языках Python и Go, и распространяется под лицензией Apache 2.0. Экземпляры ClusterFuzz могут запускаться на системах под управлением Linux, macOS и Windows, а также в различных облачных окружениях.
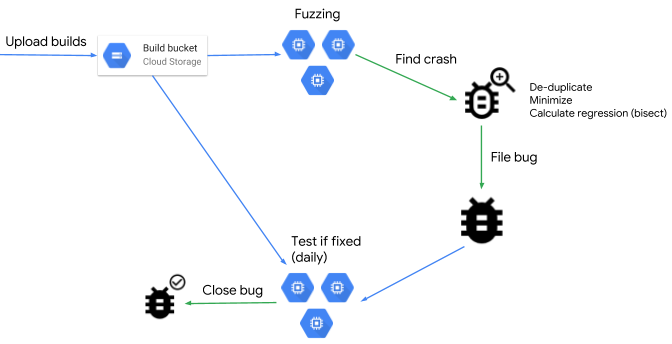
ClusterFuzz с 2011 года используется в недрах Google для выявления ошибок в кодовой базе Chrome и для обеспечения работы проекта OSS-Fuzz, в рамках которого было организовано непрерывное fuzzing-тестирование открытого ПО. Всего за время работы ClusterFuzz было выявлено более 16 тысяч ошибок в Chrome и более 11 тысяч ошибок в 160 открытых проектах, принимающих участие в программе OSS-Fuzz. Благодаря непрерывному процессу проверки актуальной кодовой базы ошибки обычно вылавливаются в течение нескольких часов после внесения в код вызывающих их изменений.
Система изначально рассчитана на организацию распределённого тестирования на большом числе узлов - например, внутренний кластер ClusterFuzz в Google включает более 25 тысяч машин (!).
ClusterFuzz поддерживает различные режимы fuzzing-тестирования на базе инструментов AddressSanitizer, MemorySanitizer, Control Flow Integrity, LibFuzzer и AFL, в том числе тестирование в режиме "чёрного ящика" (проверка произвольного бинарного кода без обработки на этапе компиляции).
В процессе тестирования автоматически отсеиваются дубликаты крахов, выявляются регрессии в коде (bisection, определение изменения в коде, после которого стал проявляться крах), анализируется статистика о производительности тестирования и интенсивности выявляемых крахов. Для управления и анализа результатов работы используется web-интерфейс.
Напомним, что при fuzzing-тестировании осуществляется генерация потока всевозможных случайных комбинаций входных данных, приближенных к реальным данным (например, html-страницы с случайными параметрами тегов, архивы или изображения с аномальными заголовками и т.п.), и фиксация возможных сбоев в процессе их обработки. Если какая-то последовательность приводит к краху или не соответствует ожидаемой реакции, то такое поведение с высокой вероятностью свидетельствует об ошибке или уязвимости.
| 

