 |
Использование в Linux дискретной видеокарты AMD Radeon вместе со встроенной Raven Ridge |
Автор: nobody
[комментарии]
|
| | Разговор пойдёт об AMD APU Ryzen 3 2200G, Ryzen 5 2400G и подобных им.
В обсуждениях на англоязычных форумах упоминается, что iGPU Vega10 более
технологически продвинут, и, в принципе, он может быть использован как
ведущий адаптер для dGPU предыдущих версий GCN 1,2,3 в рамках модели
памяти iGPU Vega10 (GCN 5).
Однако, с одной стороны это потребует большое количество человеко-часов для
написания таких драйверов под OS Linux. А, с другой стороны, новые адаптеры
линии RDNA полностью соответствуют этой модели памяти. И, в принципе,
состыковка iGPU Vega10 с dGPU RDNA, есть задача более простая и более перспективная.
Поэтому, в ближайшее время нормальной состыковки видеокарт GCN 1,2,3 и iGPU
Vega10 (GCN 5) в Linux, судя по всему, ожидать не приходится.
Соответственно, всё, что описано далее, это воркэраунд для сложившейся ситуации.
Пошаговая инструкция
Вот работоспособная конфигурация:
(01) Устанавливаем Fedora 31 (я использовал версию с MATE GUI).
Не забываем сразу добавить пользователя в группу video .
(02) Загружаем пакет kernel-5.3.16-300.fc31.src.rpm, и разворачиваем его для
компиляции в ${HOME}/rpmbuild/SOURCES/
(03) Идём на страничку
https://github.com/RadeonOpenCompute/ROCK-Kernel-Driver/issues/66 и загружаем
оттуда патч под нашу версию ядра
0003-allows-to-choose-iGPU-or-dGPU-memory-management-mode.patch.txt
по ссылке
https://github.com/RadeonOpenCompute/ROCK-Kernel-Driver/files/3614247/0003-allows-to-choose-iGPU-or-dGPU-memory-management-mode.patch.txt
Попутно читаем на английском про особенности работы встроенной карты, там много удивительного.
Выжимка, кому интересно, иначе можно пропустить:
модель памяти у iGPU и dGPU различна;
драйвер amdkfd по умолчанию использует модель памяти адаптера, проинициализировавшегося первым;
не смотря на то, что dGPU может быть первым и будет использована его модель
памяти, тем не менее iGPU Vega10 более технологически продвинут и именно он
получит первый номер во внутреннем дереве топологии драйвера amdkfd, что в
общем-то неправильно, так как карта адаптеров и фактическое их наличие не будут
соответствовать друг другу. Как результат, оба GPU будут нерабочими в ROCm (и
не только в нём);
двое разработчиков ROCm под никами fxkamd и Djip007 сформировали патч
для драйвера amdkfd, позволяющий на этапе загрузки ядра сказать драйверу
amdkfd, какую модель памяти использовать и какие адаптеры допустимы в дереве
топологии amdkfd, скажем "Большое Спасибо!" им за это.
(04) Копируем патч в каталог ${HOME}/rpmbuild/SOURCES/
$ cp 003-allows-to-choose-iGPU-or-dGPU-memory-management-mode.patch.txt ${HOME}/rpmbuild/SOURCES/003-allows-to-choose-iGPU-or-dGPU-memory-management-mode.patch
Исправляем в kernel.spec
%global baserelease 300
на произвольное большее
%global baserelease 307
Добавляем в kernel.spec после описания всех патчей, после строки
Patch536: .....
строку с описанием нового патча
Patch537: 0003-allows-to-choose-iGPU-or-dGPU-memory-management-mode.patch
как раз перед строкой
# END OF PATCH DEFINITIONS
Делаем линк kernel.spec:
$ cd ${HOME}/rpmbuild/SPECS/
$ ln ../SOURCES/kernel.spec
Запускаем сборку пакетов ядра с патчем:
$ rpmbuild -ba --nodebuginfo --target x86_64-redhat-linux --define "%_without_debug 1" --define "%set_build_flags echo" --define "%make_build make" --define "%make_install make install DESTDIR=%{buildroot}" kernel.spec
Внимание, потребуется много места на диске!
В моём случае сборки для x86_64 конфигов это было около 27 GB временных файлов.
По завершении сборки в директории ${HOME}/rpmbuild/RPMS/x86_64/
будут лежать новые пакеты:
kernel-5.3.16-307.fc31.x86_64.rpm
kernel-core-5.3.16-307.fc31.x86_64.rpm
kernel-debuginfo-5.3.16-307.fc31.x86_64.rpm
kernel-debuginfo-common-x86_64-5.3.16-307.fc31.x86_64.rpm
kernel-devel-5.3.16-307.fc31.x86_64.rpm
kernel-modules-5.3.16-307.fc31.x86_64.rpm
kernel-modules-extra-5.3.16-307.fc31.x86_64.rpm
Устанавливаем это новое ядро и его модули (естественно, с опцией --nogpgcheck).
(05) Обновляем загружаемый микрокод для видеокарт:
# dnf upgrade linux-firmware libclc
(06) Добавляем в настройки dracut несколько опций
# cat /etc/dracut.conf.d/my20200224.conf
add_drivers+=" amd_iommu_v2 amdgpu nvme_core nvme "
fw_dir+=" /lib/firmware/amdgpu "
install_items+=" /lib/firmware/amdgpu/raven_* /lib/firmware/amdgpu/polaris* "
(07) Аккуратно настраиваем X-сервер в /etc/X11/xorg.conf.
Чтобы он видел dGPU как первичный адаптер, а iGPU , как вторичный адаптер без экрана.
Однако к монитору iGPU должен быть подключен физически (или к его HW-эмулятору).
Создаём шаблон xorg.conf командой:
# X -configure
Затем копируем его в /etc/X11/xorg.conf и редактируем, оставляя:
Layout0 с двумя картами Card0 и Card1
Card0 это первичный dGPU с монитором и экраном, с точным указанием BusID
Card1 это вторичный iGPU без монитора и без экрана, с точным указанием BusID
Например:
Section "Device"
# dGPU
Identifier "Card0"
Driver "amdgpu"
BusID "PCI:1:0:0"
Option "TearFree" "True"
Option "Accel" "True"
EndSection
Section "Device"
# iGPU
Identifier "Card1"
Driver "amdgpu"
BusID "PCI:9:0:0"
EndSection
Ваши GPU могут иметь другие номера на шине pci, смотрим командой:
# lspci -v
.....
Пропускаем секции "Monitor1" и "Screen1" для iGPU в нашем случае, как это
регламентировано в мануале для xorg.conf.
Просто комментируем соответствующие разделы:
#Section "Monitor"
# Identifier "Monitor1"
.....
#Section "Screen"
# Identifier "Screen1"
.....
(08) Добавляем опцию для kfd из рекомендаций установки ROCm:
# cat /etc/udev/rules.d/70-kfd.rules
SUBSYSTEM=="kfd", KERNEL=="kfd", TAG+="uaccess", GROUP="video", MODE="0660"
Это позволит работать с dGPU пользователю из группы video.
(09) Перегенерим initramfs:
# dracut --force --kver 5.3.16-307.fc31.x86_64
(10) Добавляем в настройки grub2 несколько опций ядра для загрузки:
amd_iommu=fullflush iommu=pt video=efifb:off amdgpu.rocm_mode=2
(11) Дополнительно, устанавливаем воркэраунд от некогерентности кэша для GCN 1,2,3,5 видеокарт:
# cat /etc/environment
AMD_DEBUG=nongg,nodma
RADV_DEBUG=nongg
DRI_PRIME=0
К сожалению, воркэраунды снижают производительность от 1.5 до 15 раз (судя по
тесту Glmark2), но зато дают стабильность GUI-десктопу.
Для RDNA 1,2 видеокарт вроде бы это не нужно, но я не проверял, так как не на чем.
Перезагружаемся.
(12) Настраиваем в EFI dGPU как первичную видеокарту, а iGPU, соответственно,
становится вторичной видеокартой, урезаем ей RAM до 64 MB. Загружаемся.
Вот и всё.
Проверка
Теперь проверяем корректность результата.
# dmesg | grep -i -e amdgpu -e kfd -e drm -e ttm -e atomic -e crat
.....
[ 3.414606] kfd kfd: Ignoring ACPI CRAT on disabled iGPU (rocm_mode!=ROCM_MODE_IGPU)
.....
[ 3.667325] kfd kfd: added device 1002:wxyz
.....
[ 3.733956] kfd kfd: skipped DID 15dd, don't support dGPU memory management models
.....
Выбрана модель памяти для dGPU, добавление iGPU в топологию kfd пропущено, а
топология kfd для dGPU сформирована правильно.
# lspci -nnk -d 1002:
01:00.0 VGA compatible controller [0300]: Advanced Micro Devices, Inc. [AMD/ATI] .....
Subsystem: .....
Kernel driver in use: amdgpu
Kernel modules: amdgpu
09:00.0 VGA compatible controller [0300]: Advanced Micro Devices, Inc. [AMD/ATI] Raven Ridge [Radeon Vega Series / Radeon Vega Mobile Series] [1002:15dd] (rev c8)
Subsystem: .....
Kernel driver in use: amdgpu
Kernel modules: amdgpu
09:00.1 Audio device [0403]: Advanced Micro Devices, Inc. [AMD/ATI] Raven/Raven2/Fenghuang HDMI/DP Audio Controller [1002:15de]
Subsystem: .....
Kernel driver in use: snd_hda_intel
Kernel modules: snd_hda_intel
Всем видны оба видео-адаптера AMD на pci шине: и dGPU и iGPU.
Важно, чтобы неиспользуемый iGPU контроллировался ядерным драйвером amdgpu.
Если этого не будет (например, можно удалить устройства из дерева pci
средствами udev на раннем этапе загрузки), то iGPU будет сильно греть APU (max
75*C вместо max 60*C). И это при том, что сам iGPU вообще не будет никак
использоваться. Может возникнуть впечатление, что появились проблемы с кулером
APU, но это не так.
$ less /var/log/Xorg.0.log
[ 15.962] (**) ServerLayout "Layout0"
[ 15.962] (**) |-->Screen "Screen0" (0)
[ 15.962] (**) | |-->Monitor "Monitor0"
[ 15.962] (**) | |-->Device "Card0"
[ 15.962] (**) | |-->GPUDevice "Card1"
[ 15.962] (**) |-->Input Device "Mouse0"
[ 15.962] (**) |-->Input Device "Keyboard0"
.....
[ 15.964] (II) xfree86: Adding drm device (/dev/dri/card0)
[ 15.970] (II) xfree86: Adding drm device (/dev/dri/card1)
[ 15.973] (--) PCI:*(1@0:0:0) .....
[ 15.973] (--) PCI: (9@0:0:0) .....
.....
[ 15.979] (II) LoadModule: "amdgpu"
[ 15.980] (II) Loading /usr/lib64/xorg/modules/drivers/amdgpu_drv.so
.....
[ 15.983] (II) AMDGPU: Driver for AMD Radeon:
All GPUs supported by the amdgpu kernel driver
[ 15.983] (II) modesetting: Driver for Modesetting Kernel Drivers: kms
[ 15.983] (II) AMDGPU(0): [KMS] Kernel modesetting enabled.
.....
Т.е. видим, что X-сервер обнаружил обе видеокарты, но активно использует только
одну и именно дискретную видеокарту.
Далее можем, например, установить ROCm 3 _без_ dkms драйвера в соответствие с родной инструкцией:
# dnf install rocm-dev rocm-libs
Следующие программы дополнительно покажут корректность описанной выше пошаговой настройки.
rocm-smi нормально отображает всю статистику по dGPU и управляет ею.
rocminfo отрабатывает без ошибок и отображает 2 вычислительных агента CPU и gfx803.
clinfo отрабатывает без ошибок и отображает 1 платформу AMD-APP и 1
устройство gfx803 (не считая Mesa Clover и Pocl).
hashcat видит устройство и работает нормально. (Самосборный пакет из
оригинальных исходников, т.к. из репозитория Fedora 31 сборка имеет урезанную
функциональность и проблемы с запуском.)
Компилятор AOMP в составе ROCm 3.1 проходит успешно 67 тестов из 69 из
приложенного набора тестов smoke.
vainfo , vdpauinfo отрабатывают нормально.
Итоги
В результате настройки получаем устойчивый GUI-десктоп с корректно работающим
dGPU и с условно корректно отключенным, "не используемым" iGPU.
Дополнительно
PS:
Пока удалось нарушить работу dGPU, только используя в Avidemux HW-кодер "Intel AVC HW (VA)".
В то же время HW-кодер "Intel HEVC" в Avidemux работает довольно быстро.
А "Intel H264" не работает совсем, и, судя по всему, встройка тут не при чём.
Запуск командой:
$ ( DRI_PRIME=1 avidemux3_qt5 )
позволяет использовать встроенные HW-кодеры "не используемого" iGPU, работают они примерно так же.
PPS:
В принципе, в ядро 5.6 были добавлены полезные патчи для Raven iGPU, и, с
применением воркэраунда для Mesa 19.2.8
# cat /etc/environment
AMD_DEBUG=nongg,nodma,nodcc
RADV_DEBUG=nongg
DRI_PRIME=0
стало возможным использовать Raven iGPU как первичную видеокарту в EFI, а dGPU
использовать вторичной видеокартой.
Соответственно, просто меняем местами BusID карт в xorg.conf , и включаем
вторичную dGPU в MATE: меню System -> Control Center -> Displays -> второй
дисплей , ON , Applay , Close (настройка сохраняется в ${HOME}/.config/dconf/).
В этом случае производительность dGPU в графике снижается.
Зато появляется возможность работать с tensorflow-rocm при 100% нагрузке dGPU
без замираний первичного экрана, и наблюдать происходящее в процессе.
И, однако, попутно выясняется, что ядро 5.6.8 (со своим таким же патчем с той
же веб-странички) _не_ загружается с primary dGPU в EFI.
Возможно, что для сочетаний конкретных APU и MainBoard это вылечится
обновлением Grub2 до актуальной версии.
Вероятно, старая версия Grub2 неправильно транслирует какие-то параметры ядру из EFI.
Этот момент и более поздние версии ядер 5.6.n и 5.7.n , пардон, проверить не
успел, т.к. заапгрейдил APU на обычный CPU Ryzen без iGPU.
Перспективы
Общие соображения, которые с одной стороны можно было бы и не добавлять в
статью, а с другой, почему бы и не добавить.
Судя по всему, RDNA 1 и 2 как архитектуры GPU есть шаги по направлению к
когерентной архитектуре Gen-Z.
Это означает, что:
основной свичованой шиной станет CCIX как приоритезированный PCIe Gen4 (и выше)
RAM будет выделена в отдельные модули на CCIX-шине
контроллер памяти будет в диспетчере и каждом модуле RAM
кэши CPU, GPU, RAM, плат расширения будут когерентны
IOMMUv2 (или выше) будет обязателено by design
GPU станут более самостоятельными относительно CPU (как вычислительные устройства)
iGPU / APU не вполне вписываются в эту концепцию
Выводы, конечно же, каждый сделает сам.
|
| |
 |
|
|
Установка прав на использование USB сканера в Ubuntu 8.10 |
Автор: kmax
[комментарии]
|
| | В правилах udev не было моего сканера, и поэтому сканер работал только через sudo
$ sudo scanimage -L
device 'gt68xx:libusb:003:003' is a Mustek ScanExpress 1248 UB flatbed scanner
$ scanimage -L
No scanners were identified. If you were expecting something different,
check that the scanner is plugged in, turned on and detected by the
sane-find-scanner tool (if appropriate). Please read the documentation
which came with this software (README, FAQ, manpages).
Решение.
смотрим:
$ sudo sane-find-scanner
видим:
found USB scanner (vendor=0x055f, product=0x021f [USB Scanner], chip=GT-6816) at libusb:003:002
Если в правилах udev для сканеров нет vendor=0x055f, product=0x021f, то файлу
устройства не присвоят правильную группу
$ sudo vi /etc/udev/rules.d/50-libsane-extras.rules
(у вас может быть другой файл, найти его не составит труда)
И по аналогии добавляем наш сканер
добавляем в группу scanner всех нужных пользователей
$ sudo vi /etc/group
$ sudo /etc/init.d/udev restart
$ scanimage -L
device 'gt68xx:libusb:003:002' is a Mustek ScanExpress 1248 UB flatbed scanner
xsane тоже заработал
Те же действия могут помочь в аналогичных ситуациях с другими редкими устройствами
|
| |
|
|
|
JFFS и мониторинг активности wifi на роутере Linksys WRT54GL (доп. ссылка 1) |
Автор: Sergey Volhin
[обсудить]
|
| | Расскажу о двух возможностях, которые можно реализовать на роутере
с прошивкой DD-WRT на примере роутера Linksys WRT54GL.
1) Файловая система JFFS.
На роутере можно без труда организовать небольшое энергонезависимое хранилище файлов.
Для этого в веб-интерфейсе включаем поддержку jffs (по туториолу из официального вики dd-wrt):
1. Откройте вкладку "Administration".
2. Перейдите к секции "JFFS2 Support".
3. Кликаем "Enable JFFS".
4. Затем жмём "Save".
5. Ждём несколько секунд и жмём "Apply".
6. Опять ждём. Идём обратно к опции "Enable JFFS", кликаем "Clean JFFS".
7. Не кликая "Save", жмём вместо этого "Apply".
Теперь если мы приконнектимся к роутеру по ssh команда "df -h" расскажет нам о
наличие новой файловой системы,
смонтированной в каталоге /jffs/, и её размере (размер очень сильно зависит от
типа вашей прошивки,
для получения хоть сколько-нибудь полезного свободного пространства для jffs
рекомендуется установить mini-версию dd-wrt).
2) Индикация активности wifi по лампе на корпусе роутера.
Теперь используем возможности jffs - разместим на ней скрипт (с того же вики
dd-wrt), который заставляет
гореть лампу янтарным светом при подключенных wifi-клиентах и мигать белым при
трансфере данных через WLAN.
Для установки скрипта:
1. Коннектимся по ssh.
2. Переходим в каталог /jffs/ и создаем директорию bin:
# cd /jffs/
# mkdir ./bin
3. Как видно /jffs/bin уже прописан в переменной поиска команд PATH:
# echo $PATH
/bin:/usr/bin:/sbin:/usr/sbin:/jffs/sbin:/jffs/bin:/jffs/usr/sbin:/jffs/usr/bin
4. Создаем файл скрипта (# vi ./wlan.sh) со следующим содержанием:
#!/bin/sh
I=`nvram get wl0_ifname`
while sleep 1; do
if [ "`wl assoclist`" != "" ]; then
XFER=`ifconfig $I|grep bytes`
if [ "$XFER" != "$PXFER" ]; then
LED='gpio disable 3 ; gpio disable 2'
PXFER=$XFER
else
LED='gpio disable 3 ; gpio enable 2'
fi
else
LED='gpio enable 3 ; gpio enable 2'
fi
if [ "$LED" != "$PLED" ]; then
eval $LED
PLED=$LED
fi
done
5. Делаем скрипт исполняемым:
# chmod +x ./wlan.sh
Готово!
Скрипт теперь можно запускать командой wlan.sh или прописать в автозагрузку.
Оригинал в блоге по ссылке: http://damnsmallblog.blogspot.com/2008/03/jffs-wifi-linksys-wrt54gl.html
|
| |
|
|
|
Как избавиться от щелчков при запуске приложений на системах с чипами Intel (доп. ссылка 1) |
Автор: Аноним
[комментарии]
|
| | При щелчках в колонках в процессе работы следует выключить режим
энергосбережения у звукового драйвера:
sudo tee /etc/modprobe.d/snd-hda-intel.conf <<< "options snd_hda_intel power_save=0"
|
| |
|
|
|
Решение проблемы с исчезновением устройств вывода звука в Ubuntu 20.04 (доп. ссылка 1) (доп. ссылка 2) |
Автор: Аноним
[комментарии]
|
| | Пропал звук. Pulseaudio показывает в качестве выходного устройства Dummy Output.
Звуковая карта snd-hda-intel. Манипуляции
echo "options snd-hda-intel model=generic" | sudo tee -a /etc/modprobe.d/alsa-base.conf
echo "options snd-hda-intel dmic_detect=0" | sudo tee -a /etc/modprobe.d/alsa-base.conf
echo "blacklist snd_soc_skl" | sudo tee -a /etc/modprobe.d/blacklist.conf
с перезагрузкой не дали ничего. Потом стал вспоминать, что делал до того, как
исчез звук. Подключал Bluetooth колонки.
Залез в настройки Bluetooth, потёр всё. Звук появился. Какой-то глюк в bluez5.
В другой ситуации звук исчез (также остался только "dummy output") после
обновления с Ubuntu 18.04 до 20.04. Помогло удаление пакета timidity:
sudo apt purge timidity-daemon
|
| |
|
|
|
Решение проблемы с зависанием графической подсистемы на компьютерах с APU AMD (доп. ссылка 1) |
[комментарии]
|
| | При использовании ядер Linux 5.2+ на компьютерах с APU AMD (например, Ryzen 5)
отмечаются зависания графической подсистемы, устраняемые только перезагрузкой.
При зависании в логе отображаются записи вида "drm:amdgpu... Waiting for fences
timed out or interrupted!".
Кроме отката системы на старые выпуски ядра Linux, в качестве обходного
варианта блокирования проблемы помогает загрузка ядра с параметром "amdgpu.noretry=0".
|
| |
|
|
|
Отключение wakeup для PCIe устройств |
Автор: Аноним
[комментарии]
|
| | Краткий экскурс в историю или как это было раньше.
В файле /proc/acpi/wakeup перечислены устройства и возможность пробуждать
компьютер из S3 с их стороны. Структура файла wakeup достаточна проста:
<acpi device name> <S-state> <Status> <Sysfs node>
Небольшой пример
cat /proc/acpi/wakeup | grep enabled
EHC1 S4 *enabled pci:0000:00:1d.0
XHC S4 *enabled pci:0000:00:14.0
LID0 S3 *enabled platform:PNP0C0D:00
Для отключения замечательной функции "Пробуждение по клику мышки" ранее требовалось просто сделать
echo EHC1 > /proc/acpi/wakeup
Современность
А в современном мире устройств стало много, а имена им в dsdt таблице стали давать одинаковые.
Небольшой пример:
PXSX S4 *enabled pci:0000:08:00.0
PXSX S4 *enabled pci:0000:09:00.0
XHC S4 *disabled pci:0000:00:14.0
Все эти устройства - usb-контроллеры. В результате дублирования имён echo PXSX больше не работает.
Лечение
Вместо отключения через /proc/acpi/wakeup необходимо отключить возможность пробуждения через /sys
echo disabled > /sys/bus/pci/devices/0000\\:08\\:00.0/power/wakeup
echo disabled > /sys/bus/pci/devices/0000\\:09\\:00.0/power/wakeup
В результате в /proc/acpi/wakeup статус изменится
PXSX S4 *disabled pci:0000:08:00.0
PXSX S4 *disabled pci:0000:09:00.0
XHC S4 *disabled pci:0000:00:14.0
|
| |
|
|
|
Способ обхода краха Firefox и OpenGL приложений из-за ошибки в видеодрайвере Intel (доп. ссылка 1) |
[комментарии]
|
| | В Ubuntu 14.04 и более новых выпусках при использовании KMS-драйвера i915 на
системах со старыми видеочипами Intel 965GM, обычно используемыми в связке с
CPU Intel Core 2 Duo, периодически начинают падать OpenGL-приложения.
После загрузки некоторое время всё нормально, но после выхода из сна или
перехода в полноэкранный режим попытка обращения к OpenGL приводит к выводу
такой ошибки:
$ glxgears
intel_do_flush_locked failed: Input/output error
Неприятность ситуации в том, что в таких условиях непредсказуемым образом
начинает падать и Firefox, если на сайте используется WebGL или модные
графические трансформации.
Обходным способом решения проблемы является запуск OpenGL-программ с
программной реализацией OpenGL (включается установкой переменной окружения
LIBGL_ALWAYS_SOFTWARE=1), например, вместо прямого вызова в ярлык для запуска
Firefox можно прописать:
sh -c "LIBGL_ALWAYS_SOFTWARE=1 /usr/local/firefox/firefox"
Проблема решается установкой Mesa из репозитория xorg-edgers:
sudo apt-add-repository ppa:xorg-edgers/ppa
sudo apt-get update
sudo apt-get dist-upgrade
|
| |
|
|
|
Подключение через USB дополнительной кнопки для автоматизации запуска работ на сервере (доп. ссылка 1) |
Автор: Roman Y. Bogdanov
[комментарии]
|
| | Вводная часть: Дома есть "домашний" сервер. Этакая коробочка Lenovo
q190 размером чуть более чем DVD box. Ещё есть МФУ samsung SCX-4220. Работает
это все на ubuntu 14.04 LTS, прекрасно печатает через CUPS, прекрасно
сканирует, но вот с автоматизацией не очень.
Проблема: Дело в том, что на самсунге нет отдельной кнопки сканировать на
компьютер, которую бы можно было перехватить и скриптом запустить скан.
Внезапное решение: Недавно покупая очередную новую батарейку к своему ноутбуку
заметил на витрине магазина вот такую штуку - "USB 7.1 channel sound"
 Такие звуковушки лежат почти в каждом магазине по 200 рублей. О думаю, а что
если китайцы + кнопки и это клавиатура? Дай-те ко мне одну?
Реализация: Купил, подключил к headless q190 и стал смотреть вывод
$ lsusb
Bus 001 Device 005: ID 0d8c:013c C-Media Electronics, Inc. CM108 Audio Controller
Печально, думаю, но решил посмотреть, что ещё и в dmesg нашлось?
hid-generic 0003:0D8C:013C.0002: input,hidraw0: USB HID v1.00 Device [C-Media Electronics Inc. USB PnP Sound Device] on usb-0000:00:1a.0-1.4/input3
О, то что нужно. Отлично!
Кнопки звуковой карты - это по сути маленькая USB клавиатура. То что мне нужно.
Для обработки нажатий воспользуемся THD (Triggerhappy
- lightweight hotkey daemon) http://github.com/wertarbyte/triggerhappy
В Ubuntu 14.04 он есть "искаропки".
$ apt-get install thd
Настройка:
$ cat /etc/triggerhappy/triggers.d/brj.conf
KEY_VOLUMEDOWN 1 /home/brj/bin/scanme.sh
KEY_VOLUMEUP 1 /home/brj/grab-torrent.sh
По клавише vol down - запускается сканирование
По клавише vol up - торрент забирает свежие файлы и начинает скачку.
Скрипт запускающий сканирование:
#!/bin/sh
outscan="scan-`date +"%Y-%m-%d-%H%M%S"`"
scanimage --progress --mode Color --format=tiff --resolution 300 > /tmp/image.tiff
convert /tmp/image.tiff /home/brj/Dropbox/${outscan}.jpg
rm /tmp/image.tiff
Практическая работа: первое время дополнительно повесил звуки из super mario и
mpg123, что бы знать - работает или нет. Система работает исправно,
поэтому убрал.
Где ещё использовать? Такая штука ограничена только воображением и количеством
кнопок. Можно интернет переключать на резервный канал, сканировать, перегружать
сервера/сервисы, делать архивацию на внешний винт, вообщем на что хватит
фантазии то и автоматизировать.
Успехов
Такие звуковушки лежат почти в каждом магазине по 200 рублей. О думаю, а что
если китайцы + кнопки и это клавиатура? Дай-те ко мне одну?
Реализация: Купил, подключил к headless q190 и стал смотреть вывод
$ lsusb
Bus 001 Device 005: ID 0d8c:013c C-Media Electronics, Inc. CM108 Audio Controller
Печально, думаю, но решил посмотреть, что ещё и в dmesg нашлось?
hid-generic 0003:0D8C:013C.0002: input,hidraw0: USB HID v1.00 Device [C-Media Electronics Inc. USB PnP Sound Device] on usb-0000:00:1a.0-1.4/input3
О, то что нужно. Отлично!
Кнопки звуковой карты - это по сути маленькая USB клавиатура. То что мне нужно.
Для обработки нажатий воспользуемся THD (Triggerhappy
- lightweight hotkey daemon) http://github.com/wertarbyte/triggerhappy
В Ubuntu 14.04 он есть "искаропки".
$ apt-get install thd
Настройка:
$ cat /etc/triggerhappy/triggers.d/brj.conf
KEY_VOLUMEDOWN 1 /home/brj/bin/scanme.sh
KEY_VOLUMEUP 1 /home/brj/grab-torrent.sh
По клавише vol down - запускается сканирование
По клавише vol up - торрент забирает свежие файлы и начинает скачку.
Скрипт запускающий сканирование:
#!/bin/sh
outscan="scan-`date +"%Y-%m-%d-%H%M%S"`"
scanimage --progress --mode Color --format=tiff --resolution 300 > /tmp/image.tiff
convert /tmp/image.tiff /home/brj/Dropbox/${outscan}.jpg
rm /tmp/image.tiff
Практическая работа: первое время дополнительно повесил звуки из super mario и
mpg123, что бы знать - работает или нет. Система работает исправно,
поэтому убрал.
Где ещё использовать? Такая штука ограничена только воображением и количеством
кнопок. Можно интернет переключать на резервный канал, сканировать, перегружать
сервера/сервисы, делать архивацию на внешний винт, вообщем на что хватит
фантазии то и автоматизировать.
Успехов
|
| |
|
|
|
Как задействовать UVD для ускорения декодирования видео в Ubuntu Linux (доп. ссылка 1) |
[комментарии]
|
| | Для ускорения воспроизведения видео в приложениях поддерживающих API VDPAU с
использованием аппаратного декодера UVD, присутствующего в GPU AMD, следует
использовать свежую версию DRM-модуля radeon. Версия с поддержкой UVD войдёт в
состав ядра Linux 3.10, поэтому для использования UVD до выхода данной ветки
следует использовать экспериментальное ядро из репозитория drm-next.
Устанавливаем заголовочные файлы для VDPAU:
sudo apt-get install libvdpau-dev.
Пересобираем Mesa из Git-репозитория http://cgit.freedesktop.org/mesa/mesa/ При
выполнении configure следует указать опции "--with-gallium-drivers=r600 --enable-vdpau".
Добавляем в файл /etc/ld.so.conf.d/z.conf строку /usr/local/lib/vdpau и запускаем команду ldconfig.
Ставим пакеты с ядром drm-next (до того как выйдет ядро 3.10), доступные по
ссылке http://kernel.ubuntu.com/~kernel-ppa/mainline/drm-next/
Устанавливаем прошивку UVD для используемой карты AMD. Загрузить файл с
прошивкой можно на данной странице, после чего следует поместить её в
директорию /lib/firmware.
Перезагружаем систему.
Запускаем любой проигрыватель с поддержкой VDPAU.
|
| |
|
|
|
Как подружить Linux-ядро 3.x и утилиту LSI MegaCli (доп. ссылка 1) |
Автор: Andrew Okhmat
[комментарии]
|
| | С переходом на ядро Linux 3.x.x владельцы LSI RAID могут столкнуться с
неприятным явлением - утилита MegaCli или MegaCli64 перестаёт обнаруживать
RAID-контроллер. Ядро правильно определяет и корректно работает, а утилита
упорно показывает, что никакого RAID-контроллера нет. Не помогает исправить
проблему и обновление MegaCli до последней версии - 8.02.16.
Если мониторинг состояния RAID построен на этой утилите, то ситуация становится
совсем неприятной, так как. можно пропустить вышедший из строя жесткий диск или
пришедшую в негодность батарейку кэша.
Попробуем разобраться в ситуации и найти временное решение, до выхода новой версии MegaCli.
Посмотрим версию ядра, наличие LSI MegaRAID и вывод утилиты MegaCli:
[root@farm2:1 ~]# uname -a
Linux farm2.localdomain 3.2.5-3.fc16.x86_64 #1 SMP Thu Feb 9 01:24:38 UTC 2012 x86_64 x86_64 x86_64 GNU/Linux
[root@farm2:1 ~]# lspci | grep -i raid
10:00.0 RAID bus controller: LSI Logic / Symbios Logic MegaRAID SAS 2108 [Liberator] (rev 05)
[root@farm2:1 ~]# /opt/MegaRAID/MegaCli/MegaCli64 -adpCount
Controller Count: 0.
[root@farm2:1 ~]# /opt/MegaRAID/MegaCli/MegaCli64 -v
MegaCLI SAS RAID Management Tool Ver 8.02.16 July 01, 2011
(c)Copyright 2011, LSI Corporation, All Rights Reserved.
Мы видим, что работаем под управлением linux-ядра 3.2.5, есть установленный LSI
MegaRAID и утилита MegaCli64 его не видит. До обновления использовалось ядро
2.6.39, и утилита MegaCli64 обнаруживала контроллер.
Для понимания разницы в поведении MegaCli на ядрах версий 2.6 и 3.х я
использовал gdb и strace. Оказалось, что если загружено любое ядро с номером
версии 2.6.x - используется актуальный набор системных вызовов, иначе
используются устаревшие системные вызовы ядра 2.4.x и, соответственно,
контроллер не находится. Первая мысль, которая приходит в голову: подменить
системный вызов uname для утилиты MegaCli. Воспользуемся помощью LD_PRELOAD
и несколькими строчками кода на C:
#define _GNU_SOURCE
#include <unistd.h>
#include <sys/utsname.h>
#include <sys/syscall.h>
#include <sys/types.h>
#include <string.h>
int uname(struct utsname *buf)
{
int ret = syscall(SYS_uname, buf);
strcpy(buf->release, "2.6.40");
return ret;
}
Компилируем:
mkdir fakeuname
cd fakeuname
wget http://supportex.net/files/fakeuname/fakeuname.c
gcc -Wall -fPIC -c fakeuname.c
gcc -Wall -shared -o libfakeuname.so fakeuname.o
Проверим, как будет работать утилита. При запуске будет сообщаться "фейковый"
номер версии ядра - 2.6.40, вместо 3.2.5:
[root@farm2:1 ~]# /opt/MegaRAID/MegaCli/MegaCli64 -adpCount
Controller Count: 1.
[root@farm2:1 fakeuname]# LD_PRELOAD=./libfakeuname.so /opt/MegaRAID/MegaCli/MegaCli64 -AdpAllInfo -aALL
Adapter #0
================================
Versions
================
Product Name :
Serial No : SV12345678
FW Package Build: 12.12.0-0065
...
Небольшая победа - контроллер определился!
Теперь можно с ним работать, как и раньше. А libfakeuname.so скопировать в
более удобное место (например /usr/local/lib64) и использовать в своих скриптах
совместно с LD_PRELOAD=/usr/local/lib64/libfakeuname.so.
Ссылки:
LSI MegaCLI Emergency Cheat Sheet
LSI Documents and Downloads
Debugging code with strace
Debugging with gdb
Creating and using shared libraries in Linux
Modifying a Dynamic Library Without Changing the Source Code
|
| |
|
|
|
Работа в Linux с автоматом записи и печати на DVD/CD дисках Primera Bravo XRP |
Автор: barmaley
[комментарии]
|
| | Аппарат Primera Bravo XRP позволяет автоматизировать запись данных и печать
маркировки на CD-диски, максимальная емкость 50 + 50 дисков.
Подключается это устройство через USB.
В системе появляются три устройства (через внутренний usn hub), два cdrw и lp:
usb 2-2: new high-speed USB device number 62 using ehci_hcd
usb 2-2: New USB device found, idVendor=04b4, idProduct=6560
usb 2-2: New USB device strings: Mfr=0, Product=0, SerialNumber=0
hub 2-2:1.0: USB hub found
hub 2-2:1.0: 4 ports detected
usb 2-2.1: new full-speed USB device number 63 using ehci_hcd
usb 2-2.1: New USB device found, idVendor=0f25, idProduct=0012
usb 2-2.1: New USB device strings: Mfr=1, Product=2, SerialNumber=3
usb 2-2.1: Product: CD/DVD
usb 2-2.1: Manufacturer: Primera
usb 2-2.1: SerialNumber: 1000001
usblp0: USB Bidirectional printer dev 63 if 0 alt 0 proto 2 vid 0x0F25 pid 0x0012
usb 2-2.3: new high-speed USB device number 64 using ehci_hcd
usb 2-2.3: New USB device found, idVendor=0dbf, idProduct=0700
usb 2-2.3: New USB device strings: Mfr=2, Product=3, SerialNumber=1
usb 2-2.3: Product: USB to SATA Bridge
usb 2-2.3: Manufacturer: TSI
usb 2-2.3: SerialNumber: TSI08102925ad
scsi10 : usb-storage 2-2.3:1.0
usb 2-2.4: new high-speed USB device number 65 using ehci_hcd
usb 2-2.4: New USB device found, idVendor=0dbf, idProduct=0700
usb 2-2.4: New USB device strings: Mfr=2, Product=3, SerialNumber=1
usb 2-2.4: Product: USB to SATA Bridge
usb 2-2.4: Manufacturer: TSI
usb 2-2.4: SerialNumber: TSI081029002d
scsi11 : usb-storage 2-2.4:1.0
scsi 10:0:0:0: CD-ROM PIONEER DVD-RW DVR-215D 9.13 PQ: 0 ANSI: 0
sr0: scsi3-mmc drive: 40x/40x writer cd/rw xa/form2 cdda tray
sr 10:0:0:0: Attached scsi CD-ROM sr0
sr 10:0:0:0: Attached scsi generic sg1 type 5
scsi 11:0:0:0: CD-ROM PIONEER DVD-RW DVR-215D 9.13 PQ: 0 ANSI: 0
sr1: scsi3-mmc drive: 40x/40x writer cd/rw xa/form2 cdda tray
sr 11:0:0:0: Attached scsi CD-ROM sr1
sr 11:0:0:0: Attached scsi generic sg2 type 5
На сайте производителя есть драйверы для Linux, но они работают только с
принтером (печать этикеток для CD).
Модель встроенного принтера, очень похоже, Lexmark Z80.
Работа с роботом-автоматом производится путем посылки бинарного пакета в порт
принтера (/dev/usb/lp0)
Пакет состоит из 8 байт:
заголовок [0x1B, 0x04], команда [byte], резерв [0x00, 0x00, 0x00, 0x00], сумма 7 байт [byte]
Так же, на сайте производителя, указано что, если вы хотите получить все
hex-коды, необходимо подписать Non-disclosure Agreement (NDA).
Но можно и не подписывать, основные необходимые дествия уже расписаны
пользователем davidef для модели Primera Bravo II.
Состояние устройства можно получить через чтение порта принтера.
Вы получите две строки (последняя постоянно повторяется циклически с изменениями):
binary data 1, 0x0D
binary data 2, 0x0D
Я же подведу итог:
Манипуляции с cdrw производятся как обычно через eject и cdrecord ;)
Описание команд робота, на которые я получил хоть какую то реакцию:
05 - сброс устройства, пауза ~30 сек
80 - взять с левого лотка, положить на верхний CD
81 - взять с левого лотка, положить на принтер
82 - взять с левого лотка, положить на правый лоток
83 - взять с правого лотка, положить на верхний CD
84 - взять с правого лотка, положить на принтер
85 - взять с правого лотка, положить на левый лоток
86 - взять с верхнего CD положить на принтер
87 - взять с верхнего CD положить направо
88 - взять с верхнего CD положить налево
89 - взять с верхнего CD положить вниз (нижний CD либо наружу) !! не забудьте закрыть верхний CD !!
8A - взять с принтера положить направо
8B - взять с принтера положить налево
8С - взять с принтера положить на нижний CD (либо выбросит наружу)
8D - ?
8E - каретка в центр (пауза ~10 сек, возврат)
8F - каретка в центр (пауза ~10 сек, возврат)
90 - каретка влево (пауза ~10 сек, возврат)
91 - каретка в центр (пауза ~10 сек, возврат)
92 - взять диск (с последней позиции)/положить диск
93 - открыть принтер
94 - закрыть принтер
95 - каретка налево, картриджы направо, индикаторы перемигиваются, ждет какой то команды, если неверная команда происходит reset (пауза ~30 сек)
96 - каретка налево, картриджы направо, индикаторы постоянны
97 - возврат из 96 в исходное
98 - взять с принтера положить на верхний CD (либо выбросит наружу)
99 - проверяет диски в обеих лотках (слева и справа)
9A - взять слева ?
9B - опускает каретку с диском на 1 см, таймаут 10сек, поднимает в исходное
9С - каретка направо, картрижды налево, каретка вниз до упора и устройство выключается
9D - взять слева, положить на нижний CD
9E - взять справа, положить на нижний CD
9F - взять с нижнего CD положить на принтер
A0 - взять с нижнего CD положить направо
A1 - взять с нижнего CD положить налево
A2 - взять с нижнего CD, каретка вверх, положить на нижний CD (либо выбросит наружу)
A3 - каретка в центр (пауза ~10 сек, возврат)
A4 - взять слева, положить на верхний CD, взять еще один диск слева
A5 - взять справа, положить на верхний CD, взять еще один диск слева
A6 - взять слева, положить на нижний CD, взять еще один диск слева
A7 - взять справа, положить на нижний CD, взять еще один диск слева
A8 - взять с принтера положить на нижний CD (либо выбросит наружу), аналогично 8C
A9 - каретка в центр (пауза ~10 сек, возврат)
Этого вполне достаточно для автоматизации процесса, любым скриптовым языком.
Состояние устройства:
binary data 1:
65 байт - состояние устройства, 0x43 (открыта крышка), 0x42 (робот в процессе
манипуляций), 0x49 (в готовности, обычное состояние)
binary data 2:
62 байт - количество дисков в правом лотке, после команды 99
63 байт - количество дисков в левом лотке, после команды 99
|
| |
|
|
|
Советы по увеличению автономной работы ноутбука с Debian/Ubuntu (доп. ссылка 1) (доп. ссылка 2) |
[комментарии]
|
| | 1. Включение ALPM позволит сэкономить 1-2 Вт энергии, но может привести к
повреждению данных для некоторых устройств.
echo SATA_ALPM_ENABLE=true | sudo tee /etc/pm/config.d/sata_alpm
2. Изменение фона рабочего стола на более светлый цвет для ноутбука с
LCD-экраном увеличит продолжительность работы примерно на 1%.
3. Включение режима энергосбережения RC6 для видеокарт Intel i915 через
передачу параметра ядра i915.i915_enable_rc6=1 позволит сэкономить 25-40%
энергии для устройств на базе архитектуры Sandybridge, но в редких случаях
может привести к зависанию на определённых ноутбуках.
4. Включение режима сжатия фреймбуфера (Frame Buffer Compression) для драйвера
i915 через передачу параметра ядру i915.i915_enable_fbc=1 позволит сэкономить
до 0.6 Вт.
5. Установка задержки гашения обратного хода луча вертикальной развёртки (DRM
vblank off) через параметр ядра drm.vblankoffdelay=1 сократит число вызывающих
пробуждение процессора событий (wakeup events) и возможно сэкономит немного энергии.
6. Отключение всех беспроводных подсистем, если они не используются. В
частности отключение bluetooth ("blacklist bluetooth" в
/etc/modprobe.d/blacklist.conf) приведёт к экономии 1-2 Вт.
7. Отключение web-камеры ("blacklist uvcvideo" в
/etc/modprobe.d/blacklist.conf) поможет сэкономить 1-2 Вт.
8. Использование утилиты PowerTop для перевода следующих устройств в состояние
экономного потребления энергии:
* Webcam
* Audio
* DRAM
* Ethernet
* Wifi
* Bluetooth
* SATA
* MMC/SD
9. Использование ядра Linux в котором решена проблема с активацией ASPM
(Active State Power Management) для карт PCI Express. Ядро тестовой ветки
Ubuntu 12.04 уже содержит нужный патч. Для других систем рекомендуется в
качестве обходного пути передать ядру параметр
"pcie_aspm=powersave", который по умолчанию активирует режим максимальной
экономии энергии (иначе, будет использован режим максимальной
производительности). Для некоторых моделей ноутбуков данное действие может
привести к снижению энергопотребления на 10-30%.
10. Приглушение яркости экрана до 2/3 от максимального значения сэкономит 1 Вт.
11. Отключение мерцающего курсора в gnome-terminal позволит избавиться от
лишних пробуждений процессора:
gconftool-2 --type string --set /apps/gnome-terminal/profiles/Default/cursor_blink_mode off
12. Выявление проблем с излишне частым пробуждением процессора и излишней
нагрузкой на CPU для часто используемых приложений при помощи пакета
powertop или утилит eventstat и cpustat из PPA репозитория colin-king/powermanagement.
Например для выявления наиболее активных событий за 10 секунд:
sudo eventstat 10 1
Evnt/s PID Task Init Function Callback
96.10 12659 npviewer.bin hrtimer_start_range_ns hrtimer_wakeup
58.10 0 [kern sched] Load balancing tick tick_sched_timer
49.80 2026 alsa-source hrtimer_start_range_ns hrtimer_wakeup
49.30 2024 alsa-sink hrtimer_start_range_ns hrtimer_wakeup
47.20 0 kworker/0:0 hrtimer_start_range_ns tick_sched_timer
Для мониторинга в течение 60 секунд и вывода процессов, генерирующих более 5 событий в секунду:
sudo eventstat -t 5 60 1
Evnt/s PID Task Init Function Callback
54.00 2003 compiz hrtimer_start_range_ns hrtimer_wakeup
49.35 2024 alsa-sink hrtimer_start_range_ns hrtimer_wakeup
18.92 0 [kern sched] Load balancing tick tick_sched_timer
17.57 0 kworker/0:0 hrtimer_start_range_ns tick_sched_timer
16.13 0 [kern core] usb_hcd_poll_rh_status rh_timer_func
9.98 2386 gwibber-service hrtimer_start_range_ns hrtimer_wakeup
9.88 10063 desktopcouch-se hrtimer_start_range_ns hrtimer_wakeup
9.87 2382 ubuntuone-syncd hrtimer_start_range_ns hrtimer_wakeup
9.83 10109 desktopcouch-se hrtimer_start_range_ns hrtimer_wakeup
5.23 0 [kern core] hrtimer_start tick_sched_timer
12046 Total events, 200.77 events/sec
|
| |
|
|
|
Как решить проблему с отсутствием звука при использовании TV-тюнера в Ubuntu (доп. ссылка 1) |
[комментарии]
|
| | При работе с некоторыми TV-тюнерами, например с wintv hvr 950Q, в Ubuntu
наблюдаются проблемы со звуком. Каналы ловятся, но звука нет ни в одном
приложении. Решить проблему можно, организовав параллельное проигрывание звука
в фоне с ассоциированной с TV-тюнером звуковой карты.
Запускаем tvtime или другое приложение для работы с тюнером:
tvtime
Запускаем проигрывание звука. Если используется система alsa, поможет команда
arecord -D hw:1,0 -f S16_LE -c2 -r32000 | aplay -q -
Либо загружаем в PulseAudio модуль loopback:
pactl load-module module-loopback
В этом случае, возможно, так же нужно будет выбрать конкретный порт источника с
помощью pactl set-source-port.
В первом случае для прекращения перенаправления достаточно убить программу.
Во-втором - нужно будет выполнить pactl unload-module с номером загруженного
модуля (номер получите при загрузке).
Всё это можно запустить одной командой, на основе которой можно создать ярлык для запуска tvtime:
tvtime | arecord -D hw:1,0 -r 32000 -c 2 -f S16_LE | aplay -q -
А вот пример скрипта для запуска с помощью pulseaudio:
tvtime &
sleep 5
pactl set-source-port alsa_input.pci-0000_0d_00.0-usb-0_1.analog- stereo analog-input-video
pactl load-module module-loopback source="alsa_input.pci-0000_0d_00.0-usb-0_1.analog-stereo" source_dont_move=true
В последнем случае мы указываем конкретный источник
(alsa_input.pci-0000_0d_00.0-usb-0_1.analog-stereo) и указываем, что он не
должен меняться (source_dont_move=true).
Если в системе имеется несколько звуковых карт, то вместо "hw:1,0" может
потребоваться указать другое устройство, например, "hw:2,0". Список устройств
можно посмотреть командой:
arecord -l
Для pulseaudio список можно посмотреть командой
pactl list sources
или
pacmd list-sources
|
| |
|
|
|
Настройка 3G-модема Huawei E173 в Ubuntu/Debian без использования оболочки МегаФона |
[комментарии]
|
| | Для того, чтобы модем Huawei E173 определился в системе не только как
Flash-диск, необходимо установить пакет usb-modeswitch, который можно найти в
стандартном репозитории universe:
sudo apt-get install usb-modeswitch usb-modeswitch-data
После этого модем будет определен как ttyUSB0.
$ dmesg| tail
[310579.743098] USB Serial support registered for GSM modem (1-port)
[310579.745647] option 2-3:1.0: GSM modem (1-port) converter detected
[310579.751377] usb 2-3: GSM modem (1-port) converter now attached to ttyUSB0
Если не заработало, выясняем идентификатор устройства:
$ lsusb
Bus 002 Device 050: ID 12d1:140c Huawei Technologies Co., Ltd.
Проверяем наличие файла "12d1:*" в /etc/usb_modeswitch.d, в одном из файлов
должно быть упоминание продукта "1446". Например:
# Huawei E270+ (HSPA+ modem)
DefaultVendor= 0x12d1
DefaultProduct=0x1446
TargetVendor= 0x12d1
TargetProductList="1001,1406,140c,14ac"
CheckSuccess=20
MessageContent="55534243123456780000000000000011060000000000000000000000000000"
Если файла нет, то его можно создать по вышеприведенному примеру, просто добавив строки:
DefaultVendor= 0x12d1
DefaultProduct= 0x140c
В дальнейшем модем будет доступен через /dev/ttyUSB0 и его можно настроить
вручную через запуск pppd или через конфигураторы Network Manager, kppp или
wvdial. В качестве APN следует указать - internet, в качестве логина и пароля -
gdata/gdata, номер - "*99#".
Аналогично настраиваются соединения для работы с модемами других сотовых
операторов. Для МТС значение APN internet.mts.ru, логин/пароль - mts, для
Beeline APN - internet.beeline.ru, логин/пароль - beeline.
|
| |
|
|
|
Установка mplayer на телевизор SHARP 42SH7 (доп. ссылка 1) |
Автор: Михаил
[комментарии]
|
| | Как известно, у LCD-телевизора SHARP 42SH7 есть USB-вход, над которым написано
SERVICE. Любая попытка подключить туда флэшку с видео не приведет к успеху. И
это логично, ведь через USB нужно сначала залить медиаплеер! Все дело в том,
что этот телевизор содержит функцию показа телетекста и имеет четыре банка
памяти, куда загружаются растеризованные шрифты. Так как иероглифы нам не
нужны, то мы оставим только английский язык, а в освободившуюся память
используем под mplayer, мощный и быстрый плеер с поддержкой проигрывания
множества видео и аудио-форматов.
Для начала надо скачать архив с сайта sharp-club.net (ссылка для загрузки
доступна только зарегистрированным пользователям). Кроме архива нужна-USB
клавиатура, калькулятор и оригинальный японский телевизор SHARP 42SH7.
Внимание! Все телевизоры с локализацией, без возможности смены языка на
оригинальный японский - урезаны по функциональности, вместо четырех банков
памяти содержится только один. Попытка перезаливки на такой телевизор приведет
к его поломке и отказу сервисной службы в его ремонте! Использовать
предложенную прошивку можно только обладателям нормального "японца". В
приложенном архиве лежат следующие файлы:
service.iso
firmwaresh7.bin
sh7hack.bin
mplayer.bin
english.tbz
mplayer.tar.gz
ddump.exe
Самое главное - это service.iso. Его надо залить на любую флешку, но не в виде
файла, а побайтово, так как это - образ загрузки. Используйте стандартную
Unix-утилиту dd или, в случае использования Windows, программу ddump.exe из
комплекта. Вся информация будет удалена с флешки. После заливки надо будет
залить на флешку файлы из архива:
firmwaresh7.bin
sh7hack.bin
mplayer.bin
english.tbz
mplayer.tar.gz - это исходный код плеера с нужными патчами, его можно
переделать под свои нужды, например - добавить русский язык.
У пользователей Linux проблем с копированием файлов не возникнет. Из Windows
просто так файлы не залить, потому что на флешке используется файловая система
ext2. Если под рукой нет Linux, придется искать и ставить драйвер.
Переключите в телевизоре язык на английский. Вставьте флешку и включите
телевизор. Через 30-70 секунд вы увидите иероглифы. Это значит, что ваша
прошивка сохранилась на флешку, а в телевизор влилась заводская прошивка.
Выньте флешку, вставьте usb-клавиатуру, выключите телевизор и включите снова.
Вы перешли в режим инженерной работы с телевизором, интерфейс которого
базируется на пакете Busybox. Теперь главное ничего не перепутать!
Введите следующую команду:
du -hs /var/ram/tvtext
Появившееся на экране число - размер шрифтов с поддержкой юникода, точнее, их
растеризованный размер. Проверьте, что у вас выдает 8M или 16M. Если это не
так, значит, у вас маленький размер банков памяти, и ничего не выйдет -
выключите свой телевизор, вставьте флешку и включите его. Загрузится
оригинальная прошивка firmwaresh7.bin и все станет, как и было раньше. Дальше
можно не читать...
Итак, самый ответственный момент. В случае ошибки - обратного пути не будет.
Обратите внимание, что сейчас придется работать в редакторе vi. Эффективность
данного редактора в полной мере могут оценить только имеющие опыт работы в vi.
Для тех, кто имеет опыта работы в vi, лучше предварительно прочитать
инструкцию, разобраться в основах редактирования и потренироваться.
Вводите следующую команду:
vi /dev/fram/etc/rc
Перейдите ниже к строке:
cat /mnt/flash/firmwaresh7.bin > /dev/fram2; reboot
И замените ее на:
cat /mnt/flash/sh7hack.bin > /dev/fram2
cat /mnt/flash/mplayer.bin > /dev/fram3
tar jxf /mnt/flash/english.tbz -C /dev/fram4
reboot
Выключайте телевизор, вставьте флешку и включайте. У вас загрузится
модифицированная прошивка, которая позволяет запускать mplayer, сам mplayer и
англоязычные шрифты. Флешку после этого можно вынимать, там будет файл типа
_00001.bin - это архив вашей оригинальной прошивки. Его лучше сохранить на
всякий случай.
Теперь в меню ТВ появился новый пункт: "mplayer". Он станет активным, когда
будет вставлена флешка с фильмами. Да, сами фильмы нужно называть только
английскими буквами, иначе они не появляются в списке меню. Фильмы должны быть
размещены на флешке, отформатированной с файловой системой ext2. FAT32
телевизор не поддерживает.
В заключение скажу, что работа плеера меня несколько огорчила. Файлы mkv
проигрываются очень плохо - звук идет нормальный, а изображение идет рывками, с
пропуском кадров. Так что нормально можно смотреть только AVI или MP3.
|
| |
|
|
|
Как установить telnet-сессию с коммутатором EdgeCore из скрипта (доп. ссылка 1) |
Автор: Андрей Сергиенко
[комментарии]
|
| | Есть известная "проблема": из скрипта (php, perl, python и т.п.) средствами
самого языка установить telnet-соединение с коммутаторами EdgeCore не
получается. Сразу после соединения свитч присылает бинарный "мусор", потом
коннект просто висит и отваливается по таймауту. Т.е. даже строки приглашения
от коммутатора получить не удается. В то же время тот же самый скрипт может
прекрасно работать по телнету с D-Link'ами.
Происходит это потому что edgecorе'ам надо согласовывать параметры терминала
при поднятии телнет-сессии. Т.е. сначала (сразу после коннекта на 23-й порт)
передать свитчу желаемые параметры сессии - и только после этого он передаст
окно приглашения и с ним можно будет работать.
Пример рабочей последовательности параметров:
0xFF 0xFD 0x03 0xFF 0xFB 0x18 0xFF 0xFB 0x1F 0xFF 0xFB 0x20 0xFF 0xFB 0x21 0xFF 0xFB 0x22 0xFF 0xFB 0x27 0xFF 0xFD 0x05
0xFF 0xFA 0x18 0x00 0x58 0x54 0x45 0x52 0x4D 0xFF 0xF0
0xFF 0xFD 0x01 0xFF 0xFC 0x01
Что интересно - в таком виде отлично работается и с edgecore'ами, и с
d-link'ами. Хотя для d-link'ов такая "инициализация" и необязательна.
|
| |
|
|
|
Сброс забытого пароля HP iLO из консоли Debian GNU/Linux (доп. ссылка 1) |
Автор: Андрей
[комментарии]
|
| | Возникла необходимость сброса утерянного пароля к iLO, на сервере HP DL360G4.
Сбросить пароль можно при помощи утилиты hponcfg, которую можно загрузить из специального
репозитория на сайте HP. Репозиторий
доступен для большого числа популярных Linux-дистрибутивов, среди которых и
Debian GNU/Linux.
Для работы утилиты потребуется установить два пакета:
hponcfg_3.1.0.0.18-19_i386.deb и hp-health_8.5.0.1.2-1_i386.deb:
wget http://downloads.linux.hp.com/SDR/psp/pool/non-free/hponcfg_3.1.0.0.18-19_i386.deb
wget http://downloads.linux.hp.com/SDR/psp/pool/non-free/hp-health_8.5.0.1.2-1_i386.deb
Устанавливаем данные пакеты и стандартный пакет binutils:
sudo apt-get install binutils
sudp dpkg -i hp-health_8.5.0.1.2-1_i386.deb
sudo dpkg -i sudo dpkg -i hponcfg_3.1.0.0.18-19_i386.deb
Настройка iLO осуществляется через xml-файлы.
Файл ilo_reset_password.xml используется для сброса пароля iLO:
<RIBCL VERSION="2.0">
<LOGIN USER_LOGIN="Administrator" PASSWORD="some_ilo_password">
<USER_INFO MODE="write">
<MOD_USER USER_LOGIN="Administrator">
<PASSWORD value="new_password"/>
</mod_USER>
</user_INFO>
</LOGIN>
</RIBCL>
В параметре PASSWORD значение new_password заменяем на необходимый пароль и выполняем команду:
sudo hponcfg -f ~/ilo_reset_password.xml
Файл ilo_network.xml используется для настройки сети iLO:
<RIBCL VERSION="2.0">
<LOGIN USER_LOGIN="Administrator" PASSWORD="iLOPassword">
<RIB_INFO MODE="write">
<MOD_NETWORK_SETTINGS>
<SPEED_AUTOSELECT value="No"/>
<FULL_DUPLEX value="Yes"/>
<NIC_SPEED value="100"/>
<DHCP_ENABLE value="No"/>
<IP_ADDRESS value="10.20.30.2"/>
<SUBNET_MASK value="255.255.255.0"/>
<GATEWAY_IP_ADDRESS value="10.20.30.254"/>
<DNS_NAME value="ILOCZC73424J4"/>
<DOMAIN_NAME value=""/>
<DHCP_GATEWAY value="No"/>
<DHCP_DNS_SERVER value="No"/>
<DHCP_STATIC_ROUTE value="No"/>
<REG_WINS_SERVER value="No"/>
<PRIM_DNS_SERVER value="0.0.0.0"/>
<SEC_DNS_SERVER value="0.0.0.0"/>
<STATIC_ROUTE_1 DEST="0.0.0.0" GATEWAY="0.0.0.0"/>
<STATIC_ROUTE_2 DEST="0.0.0.0" GATEWAY="0.0.0.0"/>
</MOD_NETWORK_SETTINGS>
</RIB_INFO>
</LOGIN>
Для загрузки отсеченных в файле конфигурации настроек выполняем:
sudo hponcfg -f ~/ilo_network.xml
Чтобы изменения подействовали требуется перезагрузка iLo, которую можно
выполнить создав файл ilo_reboot.xml:
<RIBCL VERSION="2.0">
<LOGIN USER_LOGIN="Administrator" PASSWORD="iLOPassword">
<RIB_INFO MODE="write">
<RESET_RIB/>
</RIB_INFO>
</LOGIN>
</RIBCL>
и выполнив команду
sudo hponcfg -f ~/ilo_reboot.xml
|
| |
|
|
|
Прием и отправка SMS в Linux |
[комментарии]
|
| | Для организации автоматизации приема и отправки SMS в Linux можно использовать пакет
gnokii и подключенный к системе телефон. В
простейшем случае можно использовать возможность консольной утилиты gnokii из
пакета gnokii-cli, но при необходимости более сложной автоматизации имеет смысл
воспользоваться Perl-модулем GSM::SMS или GSMD::Gnokii.
Устанавливаем gnokii, для Debian/Ubuntu:
sudo apt-get install gnokii-cli gnokii-smsd xgnokii
, где gnokii-cli - интерфейс командной строки, gnokii-smsd демон для работы с
SMS, а xgnokii - GUI интерфейс. Последние два ставим на свое усмотрение.
Подключаем телефон через USB-порт. Смотрим в /var/log/messages к какому
устройству осуществилась привязка (например, /dev/ttyACM0)
Создаем файл конфигурации /home/mc/.gnokiirc
[global]
model = AT
connection = serial
port = /dev/ttyACM0
где, model - тип устройства: AT - для большинства телефонов, series40 - для
телефонов Nokia с системой series40, gnapplet для старых телефонов Nokia Series60.
connection - тип соединения serial - USB/RS-232, irda - инфракрасный порт, bluetooth - Bluetooth.
port - порт, для USB - /dev/ttyACM0 или /dev/ttyUSB0, для Bluetooth указываем
адрес устройства ("aa:bb:cc:dd:ee:ff").
Для USB-устройств также можно попробовать сочетание connection=dku2libusb и
port = N, где N - номер устройства.
Проверяем поддерживается ли телефон:
gnokii --identify
GNOKII Version 0.6.28
IMEI : IMEI56565656565656
Manufacturer : Motorola CE, Copyright 2000
Model : GSM900","GSM1800","GSM1900","MO
Product name : GSM900","GSM1800","GSM1900","MO
Revision : R368_G_0B.A0.0FR
Для мониторинга активности:
gnokii --monitor
Возможности gnokii позволяют достаточно полно контролировать телефон, но нас
интересует работа с SMS.
Чтение SMS:
gnokii --getsms тип_памяти старт стоп
где тип_памяти: SM - для SIM-карты, ME - для внутренней памяти и MT для
комбинированных хранилищ, IN - inbox, OU - outbox. Посмотреть какое хранилище
используется на телефоне можно командой "gnokii --showsmsfolderstatus"
старт - начальная позиция сообщения
cтоп - конечная позиция сообщения, если не указать будет прочитано одно
сообщение, если указать "end" будут выведены все сообщения до конечной позиции
Пример для вывода всех сохраненных SMS:
gnokii --getsms MT 1 end
Для отправки SMS можно использовать команду:
echo "текст" | gnokii --sendsms номер
Например:
echo "тест" | gnokii --sendsms '+79094126426'
Send succeeded with reference 131!
Другой способ отправки: в комплекте с Perl-модулем SMS::Send поставляется
утилита xpl-sender, которую можно использовать не только как пример для
написания скриптов, но и отправлять через неё сообщения:
xpl-sender -m xpl-cmnd -c sendmsg.basic to=+7909344355 body="test"
Вывод содержимого адресной книги:
gnokii --getphonebook MT 1 end
Адресную книгу можно сохранить, а затем восстановить:
gnokii --getphonebook MT 1 end --vcard > phonebook.txt
gnokii --writephonebook --vcard < phonebook.txt
Настройка SMS-шлюза
В состав gnokii входит демон SMSD, который позволяет организовать работу
полноценного SMS-шлюза, на лету обрабатывающего входящие SMS. Для хранения
отправляемых и получаемых сообщений SMSD может использовать СУБД MySQL,
PostgreSQL (плагины gnokii-smsd-mysql и gnokii-smsd-pgsql) или файловое
хранилище (--module file).
Ставим недостающие пакеты:
sudo apt-get install gnokii-smsd-mysql mysql-server
Создаем БД
mysql -u smsgw
> create database smsgw;
Создаем структуру БД, используя поставляемый в комплекте с gnokii-smsd-mysql пример:
mysql -u smsgw smsgw < /usr/share/doc/gnokii-smsd-mysql/sms.tables.mysql.sql
в результате будут созданы три простые таблицы inbox, outbox и multipartinbox,
структура которых имеет следующий вид:
CREATE TABLE inbox (
id int(10) unsigned NOT NULL auto_increment,
number varchar(20) NOT NULL default '',
smsdate datetime NOT NULL default '0000-00-00 00:00:00',
insertdate timestamp DEFAULT CURRENT_TIMESTAMP,
text text,
phone tinyint(4),
processed tinyint(4) NOT NULL default '0',
PRIMARY KEY (id)
);
CREATE TABLE outbox (
id int(10) unsigned NOT NULL auto_increment,
number varchar(20) NOT NULL default '',
processed_date timestamp DEFAULT 0,
insertdate timestamp DEFAULT CURRENT_TIMESTAMP,
text varchar(160) default NULL,
phone tinyint(4),
processed tinyint(4) NOT NULL default '0',
error tinyint(4) NOT NULL default '-1',
dreport tinyint(4) NOT NULL default '0',
not_before time NOT NULL default '00:00:00',
not_after time NOT NULL default '23:59:59',
PRIMARY KEY (id)
);
CREATE TABLE multipartinbox (
id int(10) unsigned NOT NULL auto_increment,
number varchar(20) NOT NULL default '',
smsdate datetime NOT NULL default '0000-00-00 00:00:00',
insertdate timestamp DEFAULT CURRENT_TIMESTAMP,
text text,
phone tinyint(4),
processed tinyint(4) NOT NULL default '0',
refnum int(8) default NULL,
maxnum int(8) default NULL,
curnum int(8) default NULL,
PRIMARY KEY (id)
);
Запускаем smsd:
/usr/sbin/smsd -u smsgw -d smsgw -c localhost -m mysql -f /var/log/smsdaemon.log
где "-u" - имя пользователя БД, "-d" - имя базы, "-с" - хост, а "-m" - модуль хранения.
Отправив теперь SMS на подключенный к компьютеру телефон, smsd сразу перехватит
его и запишет в базу.
выполнив "select * from inbox;" увидим примерно такое:
| id | number | smsdate | insertdate |text | phone | processed |
| 1 | +7909343156224 | 2011-01-20 10:12:05 | 20110120130123 | Test | NULL | 0 |
Для отправки сообщения достаточно добавить новую запись в таблицу outbox, smsd
сразу его подхватит его и отправит. Например:
insert into outbox (number,text) values('+7909344355', 'Тест);
В заключение можно отметить, что smsd может работать без СУБД, используя
файловое хранилище. Пример запуска:
/usr/sbin/smsd -m file -c spool-директория
Для отправки SMS в spool-директории нужно создать файл с любым именем в формате:
номер
текст
после успешной отправки файл будет удален.
Через опцию "-u" можно указать путь к скрипту, который будет выполняться при
каждом получении SMS. Иначе входящие сообщения будут выводиться в стандартный
выходной поток в формате "действие номер дата < текст".
Дополнение: Вместо gnokii можно использовать интенсивно развивающийся форк [[http://wammu.eu/
gammu]], содержащий поддержку некоторых дополнительных телефонов.
|
| |
|
|
|
Настройка в Linux удаленного включения машины при помощи Wake On Lan (доп. ссылка 1) |
Автор: ashep
[комментарии]
|
| | Задача: обеспечить возможность удаленного включения компьютера с другой машины в локальной сети.
Для того, чтобы иметь возможность разбудить компьютер удалённо, необходимо,
чтобы в нём был установлен источник питания ATX версии не ниже 2.01,
материнская плата, поддерживающая Wake On Lan, а также сетевая плата с
поддержкой этой технологии.
Настройка
Определить, поддерживает ли материнская плата вашего компьютера Wake On Lan,
можно зайдя в настройки CMOS Setup в раздел настроек управления питанием.
Найдите там опцию "Wake On Lan" и убедитесь, что она включена.
После загрузки системы установите, если необходимо, пакет ethtool, при помощи
которого можно в том числе и переключать сетевую плату в режим пробуждения по
сигналу Wake On Lan от других машин:
sudo apt-get install ethtool
Далее, необходимо определить, поддерживает ли установленная сетевая плата Wake
On Lan, и включена ли эта опция:
sudo ethtool eth0 | grep -i wake-on
Supports Wake-on: pumbg
Wake-on: d
В строке Supports Wake-On перечислены механизмы, поддерживаемые сетевой платой.
В моём примере я пользуюсь методом отправки так называемым Magic Packet, и если
вам нужно то же самое, то убедитесь, что в Supports Wake On присутствует буква
"g". Буква "d" в строке Wake-on обозначает, что Wake On Lan для данного
сетевого интерфейса отключён. Чтобы включить его в режим распознавания Magic
Packet, необходимо выполнить:
ethtool -s eth0 wol g
Имейте ввиду, что после включения компьютера, вероятней всего, опция Wake-on
опять перейдёт в состояние "d" и, если вам нужно, добавьте приведённую выше
команду куда-нибудь в /etc/rc.local.
Теперь всё готово для пробуждения системы по получению Magic Packet. Для того,
чтобы его отправить, необходимо знать MAC-адрес сетевого интерфейса включаемого
компьютера, поэтому прежде, чем выключать систему, запишите его:
ifconfig eth0 | grep -i hwaddr
eth0 Link encap:Ethernet HWaddr 00:0e:2e:b9:cb:ad
Теперь можно выключать систему:
sudo shutdown -h now
Включение
Теперь с любого другого компьютера, находящегося в том же сегменте локальной
сети (в принципе, это необязательно, но тогда необходимо, чтобы в вашей сети
маршрутизаторы корректно пробрасывали широковещательные пакеты), можно включить
ранее сконфигурированную удалённую систему. Для этого понадобится утилита
wakeonlan, которую необходимо установить:
sudo apt-get install wakeonlan
Разбудить выключенную систему теперь можно командой (обратите внимание,
wakeonlan не требует прав суперпользователя):
wakeonlan -p 8 00:0e:2e:b9:cb:ad
Опцией -p указывается номер UDP-порта, с которого будет отправлен Magic Packet.
Указание этой опции обязательно, поскольку по умолчанию wakeonlan использует
девятый порт, помеченный в /etc/services как discard, что означает то, что
пакет с этого порта отправить не получится. В принципе, можно использовать
любой незанятый в системе UDP-порт.
|
| |
|
|
|
Настройка 4G WiMAX-модема на чипах Beceem в Linux |
Автор: Oddentity
[комментарии]
|
| | Недавно в инете появился Sprint 4G Depelopment Pack, содержащий исходники
драйверов и API для модемов на чипсете Beceem, а также документацию и различные
тестовые утилиты.
К сожалению, поставляемая документация местами не соотвествует, описывает
прежнюю версию драйверов и многое пришлось додумывать по ходу. В частности, там
заявлено ядро версии от 2.6.9 и выше. На самом же деле, требуется ядро минимум
2.6.29 т.к. используются некоторые функции USB Core API, которых нет в прежних
ядрах. В этом был первый долгий затык - попытка установить на CentOS 5.5.
Необходимые требования для сборки и корректной работы:
- Ядро Linux версии не ниже 2.6.29
- Административный доступ с правами root
- Пакеты linux-source, kernel-headers, openssl 0.9.8, С-compiler, usb-modeswitch и др.
В этой статье описывается установка на Ubuntu-server-10.10 i386 с ядром 2.6.35.
Используется 4G-модем Huawei BM338 на чипсете Beceem BCSM250 от провайдера
byfly (Белтелеком). Модем позиционируется как решение Mobile-WiMAX и работает
на частоте 3,5 ГГц.
Сссылка на архив Sprint 4G Depelopment Pack: http://developer.sprint.com/getDocument.do?docId=101032
1. Подготовка ядра
Устанавливаем все необходимые пакеты:
apt-get install linux-source linux-headers-$(uname -r) openssl unzip dos2unix patch
cd /usr/src
tar xvfj linux-source-2.6.35.tar.bz2
cd linux-source-2.6.35
make oldconfig && make prepare
make modules_prepare
2. Установка и настройка usb-modeswitch
Утилита usb_modeswitch необходима для автоматического переключения устройства
из режима ZeroCD (на котором драйвера для Windows) в режим модема. Если
запустить lsusb, то увидим устройство в режиме ZeroCD:
Bus 001 Device 003: ID 198f:bccd Beceem Communications Inc.
Устанавливаем:
apt-get install usb-modeswitch
cat /etc/usb_modeswitch.d/198f\:bccd >> /etc/usb_modeswitch.conf
Редактируем файл /lib/udev/rules.d/40-usb_modeswitch.rules - можно удалять
описания всех устройств, кроме Beceem. Должно остаться что-то вроде:
LABEL="modeswitch_rules_begin"
# Beceem BCSM250
ATTRS{idVendor}=="198f", ATTRS{idProduct}=="bccd", RUN+="usb_modeswitch '%b/%k'"
LABEL="modeswitch_rules_end"
Перезапускаем udev:
service udev restart
Теперь, если снова вставить модем, вывод lsusb должен быть такой:
Bus 001 Device 003: ID 198f:0220 Beceem Communications Inc.
- 198f:bccd поменялся на 198f:0220
3. Установка модуля ядра и Beceem API Library
Распаковываем скачанный архив:
tar xvfz Sprint4GDeveloperPack-1.1.tar.gz
cd Sprint4GDeveloperPack-1.1
Собираем:
./install.sh
Скрипт задаст ряд вопросов по поводу расположения директорий, главное указать
правильную директорию с исходниками ядра. В моем случае это /usr/src/linux-source-2.6.35
Скрипт соберет модуль ядра drxvi314.so, библиотеку libxvi020.so и копирует
прошивку девайса в /lib/firmware. После чего выдаст ошибку - остальные
компоненты будем собирать позже вручную. Нам еще потребуется конфиг устройства
от провайдера, берем его из папки с установленной программой в винде (Program
files/Wimax Connection Manager/Driver/Firmware/macxvi.cfg) и кладем в
/lib/firmware. Теперь загружаем модуль ядра:
modprobe drxvi314
Если все прошло удачно - на модеме должен загореться красный светодиод. Также
стоит глянуть вывод dmesg -c, там должно быть что-то типа
...
[ 6.240000]
[ 6.240035] register_networkdev:Beceem Network device name is eth1!
...
...
[ 7.197554] usbcore: registered new interface driver usbbcm
[ 7.197562] Initialised usbbcm
Для автозагрузки добавляем drxvi314 в /etc/modules
Поднимаем eth1:
ifconfig eth1 up
4. Установка Beceem Connection Manager и библиотек
unzip CSCM_v1.1.6.0_source.zip
cd CSCM
Т.к. в составе исходников не оказалось заголовочных файлов OpenSSL, качаем нужную версию с сайта:
wget http://www.openssl.org/source/openssl-0.9.8o.tar.gz
tar xvfz openssl-0.9.8o.tar.gz
и кладем заголовочные файлы в нужные места:
cp -R openssl-0.9.8o/include/openssl wpa_supplicant/openssl
cp -R openssl-0.9.8o/crypto crypto
cp -R openssl-0.9.8o/ssl ssl
cp -R openssl-0.9.8o/e_os2.h e_os2.h
cp -R openssl-0.9.8o/include/openssl BeceemEAPSupplicant/BeceemEngine/openssl
cp -R openssl-0.9.8o/crypto BeceemEAPSupplicant/crypto
cp -R openssl-0.9.8o/e_os2.h BeceemEAPSupplicant/e_os2.h
ln -s /lib/libssl.so.0.9.8 /lib/libssl.so
ln -s /lib/libcrypto.so.0.9.8 /lib/libcrypto.so
Конвертируем build.sh в UNIX-формат и собираем:
dos2unix build.sh
chmod +x build.sh
./build.sh pc_linux
В конце скрипта должно быть написано SUCCESS по всем компонентам.
Кладем библиотеки, демон и клиент в нужные места:
cp bin_pc_linux/bin/lib* /lib/
cp bin_pc_linux/bin/wimax* /usr/local/bin/
5. Конфигурирование демона wimaxd
Тут есть одна непонятная вещь, над которой тоже пришлось долго "плясать с бубном".
Ранее, при сборке модуля ядра, мы уже скопировали конфиг устройства (файл
macxvi.cfg), поставляемый провайдером. Такой же файлик есть и в архиве
Sprint'а, но с ним модем ведет себя странно (не работают светодиоды, поиск БС
происходит очень долго и т.д.). Но при этом, демон wimaxd, наоборот, корректно
работает именно с конфигом Sprint'а (с родным провайдерским конфигом были
проблемы с TLS-аутентификацией).
В общем, в /lib/firmware/ должно быть 2 файла:
macxvi.cfg - конфиг провайдера, его использует модуль ядра.
macxvi-sprint.cfg - конфиг Sprint'а из архива (лежит в
Sprint4GDeveloperPack-1.1/Rel_5.2.7.3P1_USB/Tools/config/CFG_files_for_VSG_testing/macxvi_VSG_2.6-3.5_FLASH_r37.cfg) -
он нужен для демона wimaxd
Создаем конфиг wimaxd, например /etc/wimaxd.conf
После изучения документации, а также методом проб и ошибок получилось вот такое содержимое:
/etc/wimaxd.conf:
BandwidthMHz 10
CenterFrequencyMHz 3416 3426 3436 3446 3516 3526 3536 3546
AuthEnabled Yes
EAPMethod 4
UserIdentity '6816C0B1C045@wimax.beltel.by'
ValidateServerCert Yes
CACertPath '/usr/local/beceem/certs'
CACertFileName '/usr/local/beceem/certs/ca.pem'
TLSDeviceCertFileName '/usr/local/beceem/certs/cpecert.pem'
TLSDevicePrivateKeyFileName '/usr/local/beceem/certs/cpekey.pem'
InnerNAIChange Yes
BeceemEngineFileName '/lib/libengine_beceem.so'
#AuthLogLevel 4
#AuthLogFileName '/tmp/CM_Auth.log'
FirmwareFileName '/lib/firmware/macxvi200.bin'
ConfigFileName '/lib/firmware/macxvi-sprint.cfg'
Немного пояснений.
Параметры BandwidthMHz и CenterFrequencyMHz взяты из настроек виндошной программы.
EAPMethod 4 - EAP-TLS
UserIdentity - логин. Первая часть логина до символа @ - это МАС-адрес
устройства без двоеточий. Также взят из настроек виндошной программы.
CACertPath, CACertFileName, TLSDeviceCertFileName, TLSDevicePrivateKeyFileName
- пути к файлам сертификатов и ключей. Их нужно взять из папки с установленной
программой в винде (Program Files/Wimax Connection Manager/cert/) и положить в
указанную конфигом директорию.
InnerNAIChange Yes - не знаю что это, но без этой опции ошибка аутентификации при подключении.
FirmwareFileName, ConfigFileName - пути к файлам прошивки и конфига от Sprint'a
6. Подключение
Запускаем демон:
wimaxd -D -c /etc/wimaxd.conf
Результатом правильной работы будет непрерывный вывод сообщения Link status =
WAIT FOR PHY SYNC CMD - это значит, что демон готов принимать команды от
клиента. Открываем другую консоль и запускам клиент:
wimaxc -i
Должно появится приглашение
Beceem CM Server Version 1.1.6.0
>
а в консоли демона сообщение
Client socket 00000006 lock Beceem API: SUCCESS (wait = 0 ms)
Client socket 00000006 unlock Beceem API: Success
Начинаем сканирование:
> search
Через секунд 30 клиент выдаст найденные BSIDs, что-то вроде такого:
Network search returned 4 base stations.
Idx BSID Pre Freq BW RSSI CINR
0 01:01:00:00:02:00:17:00 0x05 3416.000 10.000 -70 26
1 01:01:00:00:02:00:17:20 0x05 3426.000 10.000 -76 17
2 01:01:00:00:02:00:17:10 0x05 3436.000 10.000 -74 20
3 01:01:00:00:02:00:17:30 0x05 3446.000 10.000 -72 24
Подключаемся к той, у которой соотношение сигнал/шум максимальное, в данном случае 0
> connect 0
и если параметры аутентификации заданы верно, соединение будет установлено, а
светодиод модема сменится на зеленый с мигающим желтым. В консоли демона можно
увидеть такую информацию:
=============== Received Message Start (2010/09/24 18:03:10.622) ===========
u32State = Network Entry completed
Service flow response received (Type = 6 - Subtype = 1 - Length = 8476)
Service Flow Add Indication:
Type = 13
Direction = Uplink
Connection ID = 10039
Virtual CID = 4
Service flow ID = 513
Max sustained rate = 512 kbps
Traffic priority = 0
=============== Received Message End (type=6 sub-type=1) ===============
Device status indication: Layer 2 connected
=============== Received Message Start (2010/09/24 18:03:10.682) ===========
u32State = Network Entry completed
Service flow response received (Type = 6 - Subtype = 1 - Length = 8476)
Service Flow Add Indication:
Type = 13
Direction = Downlink
Connection ID = 10040
Virtual CID = 5
Service flow ID = 512
Max sustained rate = 2680 kbps
Traffic priority = 0
================
Link status = LINKUP ACHIEVED
Здесь видны параметры скорости даунлинка/аплинка (2680/512 kbps - ограничение провайдера).
Если соединение не установилось - нужно смотреть вывод ошибок в консоли демона
и пытаться исправить. Также будет полезно включить опции AuthLog и просмотреть
детальный лог. Вполне вероятно, для других провайдеров параметры аутентицикации
будут совсем другие.
7. Финальные шаги
После того, как все будет правильно настроено - демон можно запустить в фоне:
wimaxd -c /etc/wimaxd.conf
и занести в стартовые скрипты системы.
Клиентскую часть тоже можно автоматизировать, в документации есть пример
скрипта на Python. Но я не силен в программировании на Python, поэтому оставляю
это за рамками статьи.
Осталось настроить PPPoE-соединение к провайдеру. Тут уже все стандартно -
запускаем pppoeconf и отвечаем на вопросы. Обратите внимание, что интерфейс
eth1 изначально не поднят, перед запуском PPPoE его нужно активировать
(ifconfig eth1 up)
Стартуем:
pon dsl-provider
... и вуаля! Проверяем, поднялся ли ppp0:
ifconfig ppp0
ping ftp.mgts.by
--- ftp.mgts.by ping statistics ---
177 packets transmitted, 177 received, 0% packet loss, time 176214ms
rtt min/avg/max/mdev = 42.551/59.213/71.809/8.631 ms
Работает все хорошо, проблем замечено не было. Скорость - максимальная,
ограниченная провайдером. Субъективно, пинг стал меньше и ровнее, чем под Windows.
При подготовке статьи была использована документация из Sprint 4G Depelopment Pack.
P.S. Выражаю благодарность человеку под ником amod-cccp за предоставленный линк
на этот пак (месяц назад искал какую-либо информацию - ничего не нашел).
|
| |
|
|
|
Использование iPhone как USB-модема в Ubuntu (доп. ссылка 1) |
Автор: Юрий Евстигнеев
[комментарии]
|
| | Для настройки работу iPhone в качестве модема через USB, необходимо установить
свежие версии libimobiledevice, ipheth (iPhone USB Ethernet Driver) и gvfs из PPA-репозитория
pmcenery:
sudo add-apt-repository ppa:pmcenery/ppa
sudo aptitude update
sudo aptitude install libimobiledevice libimobiledevice-utils ipheth-utils gvfs
Включаем на телефоне режим модема.
Подключаем телефон через USB и настраиваем соединение в NetworkManager.
|
| |
|
|
|
Подключение мультимедиа клавиш на usb-клавиатуре во FreeBSD (доп. ссылка 1) |
Автор: arachnid
[комментарии]
|
| | Условие - FreeBSD не ниже 8-ки. Мультимедиа клавиши usb-шных клавиатур не
генерируют фиксированные скан-коды, поэтому этим придется заняться uhidd.
Необходимо установить
/usr/ports/sysutils/uhidd
для того, что бы связать клавиши со скан-кодами, сначала запустим uhidd следующим образом:
uhidd -o /dev/ugenX.X
где параметр "-о" значит, что обслуживать демон будет только
мультимедиа-клавиши, а номера в ugen должны ссылаться на клавиатуру.
Запускаем
usbconfig
и смотрим вывод
После запуска последовательно нажимаем все мультимедиа кнопки. на какие-то
может быть реакция, на какие-то нет - пока неважно - главное последовательно
пройтись по всем кнопкам.
в результате этого мы получим файл
/var/run/uhidd.ugenX.X/cc_keymap
следующего вида
0x046d:0xc30e={
cc_keymap={
Play/Pause="0x5A"
Mute="0x5F"
Volume_Increment="0x62"
Volume_Decrement="0x63"
AL_Consumer_Control_Configuration="0x71"
AC_Home="0x66"
}
}
где первыми идет обозначение клавиатуры (вендор:модель), а затем названия
кнопок с произвольно присвоенными скан-кодами. и вот здесь есть одна хитрость -
uhidd выбирает эти коды из списка свободных (посмотреть список можно в конце
man uhidd.conf), но может так получиться, что какие-то коды уже заняты. в таком
случае для этих клавиш надо прописать коды самостоятельно, но об этом чуть позже.
Далее создаем файл /usr/local/etc/uhidd.conf
default={
mouse_attach="NO"
kbd_attach="NO"
vhid_attach="NO"
cc_attach="YES"
}
повторяющий ту же опцию "-o", которую указывали при запуске вручную
теперь
cat /var/run/uhidd.ugenX.X/cc_keymap >> /usr/local/etc/uhidd.conf
и делаем
/usr/local/etc/rc.d/uhidd start /dev/ugenX.X
и настраиваем свой DE. правда здесь может поджидать маленькая досада -
поскольку uhidd назначает скан-коды произвольно из списка неиспользуемых,
то у меня получилось, что скан-код с одной из клавиш не обрабатывался. В
этом случае просто назначаем клавише другой скан-код из доступных.
в случае, если window manager не поддерживает назначения произвольных сканкодов
на нажатия, а обрабатывает только стандартные, тогда надо использовать
xmodmap .Xmodmap
где в .Xmodmap
keycode 170 = XF86AudioRaiseVolume
keycode 184 = XF86AudioLowerVolume
keycode 190 = XF86AudioMute
......
Ссылки на использованные материалы:
* http://wiki.freebsd.org/uhidd#head-629d89bc56c27990a707d46a32462dcdbdd3ccf7
* man uhidd
* man uhidd.conf
|
| |
|
|
|
Подключение нескольких звуковых плат через ALSA (доп. ссылка 1) (доп. ссылка 2) |
Автор: Max Tyslenko
[комментарии]
|
| | При наличии в системе 2 звуковых плат, встроенной и внешней, Kubuntu по
умолчанию для работы выбрала встроенную. Переключить вывод на внешнюю карту
можно через GUI-конфигуратор "Параметры системы" / "Мультимедиа", но интерес
представляет способ изменения активной карты из консоли.
В помощь нам придет утилита: asoundconf
$ asoundconf
Usage:
asoundconf is-active
asoundconf get|delete PARAMETER
asoundconf set PARAMETER VALUE
asoundconf list
Convenience macro functions:
asoundconf set-default-card PARAMETER
asoundconf reset-default-card
asoundconf set-pulseaudio
asoundconf unset-pulseaudio
asoundconf set-oss PARAMETER
asoundconf unset-oss
Для переключения активной карты воспользуемся командой:
$ asoundconf set-default-card PARAMETER
Вместо параметра PARAMETER нужно указать имя звуковой карты, узнать которое можно через команду:
$ asoundconf list
Names of available sound cards:
NVidia
Intel
В итоге выполняем:
asoundconf set-default-card NVidia
Второй способ - внести изменения в файл конфигурации ~/.asoundrc (локальный для
пользователя) или /etc/asound.conf, в котором прописать:
pcm.!default {
type hw
card NVidia
}
идентификатор карты можно посмотреть выполнив:
cat /proc/asound/cards
Дополнительно можно указать параметр "device", в котором привести номер
устройства вывода (колонки, наушники и т.п.). Список устройств можно посмотреть
через команду:
cat /proc/asound/devices
Прослушать заданный файл через определенное устройство можно, например, так:
aplay -D hw:0,2 file.wav
так
aplay -D plughw:0,0 file.wav
или так
mplayer file.wav -ao alsa:device=hw=0.0
|
| |
|
|
|
Организация совместного доступа к сканеру по сети (доп. ссылка 1) |
Автор: Роман Сукочев
[комментарии]
|
| | Задача: организовать совместный доступ пользователей с разных машин локальной
сети к сканеру HP Scanjet G3110, подключенному к ПК с Ubuntu Linux.
Настройка сервера к которому подключен сканер:
1. Устанавливаем пакет 'sane-utils':
sudo apt-get install sane-utils
2. Добавляем в файл конфигурации /etc/sane.d/saned.conf IP-адреса компьютеров,
которым необходимо открыть доступ к сканеру.
3. В файл /etc/inetd.conf, при использовании в Ubuntu openbsd-inetd, добавляем
или раскомментируем строку:
sane-port stream tcp nowait saned:saned /usr/sbin/saned saned
Если используется xinetd, настраиваем вызов saned по аналогии.
4. Создаем группу scanner:
sudo groupadd scanner
добавляем себя и пользователя saned в эту группу:
sudo usermod -aG scanner $USER
sudo usermod -aG scanner saned
5. Для организации доступа к сканеру из группы scanner редактируем файл /lib/udev/rules.d/40-libsane.rules
ищем там свой сканер. Выглядеть его упоминание может примерно так:
# Hewlett-Packard ScanJet G3110
ATTRS{idVendor}=="03f0", ATTRS{idProduct}=="4305", ENV{libsane_matched}="yes"
приводим строку к такому виду:
# Hewlett-Packard ScanJet G3110
ATTRS{idVendor}=="03f0", ATTRS{idProduct}=="4305", ENV{libsane_matched}="yes", MODE="664", GROUP="scanner"
Если сканера нет в списке, его нужно добавить по аналогии с остальными
сканерами. idVendor и idProduct сканера можно узнать с помощью команды:
sane-find-scanner
6. Перезагружаем компьютер для того чтобы удостовериться, что после
перезагрузки все заработает как надо, или вручную перезапускаем сервисы saned,
udev, openbsd-inetd (или xinetd).
Настройка клиентской машины
1. Устанавливаем пакет sane-utils:
sudo apt-get install sane-utils
2. В конец файла /etc/sane.d/net.conf добавляем IP-адрес сервера к которому подключен сканер.
3. Теперь можно пробовать сканировать с помощью XSane или другой подходящей
программой, используя расшаренный сканер.
На ПК, работающих под Windows, для работы с Sane-сервером можно использовать
такие клиенты, как XSane-win32 (http://www.xsane.org/xsane-win32.html) или
SaneTwain (http://sanetwain.ozuzo.net/), для Mac OS X - Twain-sane (http://www.ellert.se/twain-sane/).
Для организации сканирования на стороне клиента через web-браузер можно
использовать проект PHPSane (http://sourceforge.net/projects/phpsane/).
|
| |
|
|
|
Настройка работы CDMA модема через /dev/ttyACM0 |
Автор: Игорь Гаркуша
[комментарии]
|
| | Окружение
ОС - Fedora 11 (Russian Remix). Ядро 2.6.29.4-167.fc11.i686.PAE. Mодем Maxon
Minimax MM-5500U (CDC ACM модем). Файлы /etc/wvdial.conf, /etc/resolv.conf
настроены верно. Используется верно настроенная программа дозвона
chestnut-dialer (вер. 0.3.3) (хотя можно и без нее если установлен wvdial).
Ситуация 1.
Загружается ОС. Модем отключен. Затем модем включается и дозвон невозможен,
поскольку отсутствует файл устройства /dev/ttyACM0.
Мониторинг командой udevadm monitor показывает, что его удаляет ядро и затем Udev.
Ситуация 2.
Загружается ОС. Модем включен. Дозвон возможен (файл устройства /dev/ttyACM0
существует). Модем отключается - файл устройства /dev/ttyACM0 пропадает. При
повторном включении модема файл устройства отсутствует. В итоге дозвон невозможен.
Решение.
Подобные ситуации возникали, в частности, и в Ubuntu 9.10 и в некоторых других
Linux. Из форумов видно, что проблему рекомендуют решать перезагрузкой модуля
ядра cdc-acm и созданием файла устройства в командном режиме. Рекомендуют также
автоматизацию при помощи правил udev. Возможна даже ситуация когда имеем после
нескольких plug/unplug модема множество /dev/ttyACM0..n. И модем не
распознается. Правила udev помогают не всегда (установлено экспериментально).
Связь с модемом можно установить и при помощи представленной ниже
специально разработанной программы (тестировалась на Fedora 11 Russian Remix) и
Ubuntu 9.10 (версии udev 141 и 147 соответственно).
// File minimaxd.c
//
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <sys/types.h>
#include <signal.h>
#include <syslog.h>
#define TMP_FILE__PID "/tmp/minimaxd.pid"
#define TMP_FILE__LSUSB "/tmp/lsusbminimax.tmp"
#define PATH_CDC_ACM_MODULE "/sys/module/cdc_acm/initstate"
#define PATH_MODEM_TTY "/dev/ttyACM0"
#define CHECK_MODEM_PLUG_STR "lsusb | grep Qualcomm > /tmp/lsusbminimax.tmp"
int fileexist(const char* filename);
void kill_copy_daemon();
void start_restart();
void stop();
int CheckPlugModem();
void wait_cdc_acm_control();
int CheckPid();
void SetPid();
int GetPid();
void PrintMessageToLog(char* szMessage);
int main(int argc, char* argv[])
{
if(argc==2)
{
if((!strcmp("start",argv[1]))||(!strcmp("restart",argv[1])))
{
kill_copy_daemon();
wait_cdc_acm_control();
}
else
if(!strcmp("stop",argv[1])) kill_copy_daemon();
}
else
{
printf("Start/Restart MiniMax Modem Access:\nminimaxd start|stop|restart\n");
printf("Background start:\nminimaxd start &\n");
}
return 0;
}
int fileexist(const char* filename)
{
int res = 0;
FILE* f=fopen(filename,"rt");
if(f!=NULL) { fclose(f); res=1; }
return res;
}
void kill_copy_daemon()
{
char cmd[255]="";
int pid = GetPid();
if(pid>0)
{
kill((pid_t)(pid), SIGKILL);
strcpy(cmd,"rm -f "); strcat(cmd,TMP_FILE__PID); system(cmd);
strcpy(cmd,"rm -f "); strcat(cmd,TMP_FILE__LSUSB); system(cmd);
PrintMessageToLog("Modem service is stopped");
}
}
void start_restart()
{
system("rm -f /dev/modem");
system("rm -f /dev/ttyACM*");
system("rmmod cdc-acm");
system("modprobe cdc-acm");
system("mknod /dev/ttyACM0 c 166 0");
system("chmod 666 /dev/ttyACM*");
system("ln -s /dev/ttyACM0 /dev/modem");
PrintMessageToLog("Modem service started");
}
void stop()
{
system("rmmod cdc-acm");
system("rm -f /dev/modem");
system("rm -f /dev/ttyACM*");
PrintMessageToLog("Modem service is stopped");
}
int CheckPlugModem()
{
char str[255]="";
int res = 0;
system(CHECK_MODEM_PLUG_STR);
sleep(2);
FILE* f=fopen(TMP_FILE__LSUSB,"rt");
if(f!=NULL)
{
strcpy(str,"");
fscanf(f,"%s",str);
fclose(f);
if(strlen(str)>0) res = 1;
}
return res;
}
void wait_cdc_acm_control()
{
int fl_CDC_ACM_OK=0;
int fl_ttyACM0_OK=0;
if(!CheckPid())
{
SetPid();
while(1)
{
fl_CDC_ACM_OK=fileexist(PATH_CDC_ACM_MODULE);
if(CheckPlugModem())
{
fl_ttyACM0_OK=fileexist(PATH_MODEM_TTY);
if((fl_CDC_ACM_OK==1)&&(fl_ttyACM0_OK==0)) start_restart();
else
if((fl_CDC_ACM_OK==0)&&(fl_ttyACM0_OK==0)) start_restart();
}
else
{
if(fl_CDC_ACM_OK) stop();
}
sleep(3);
}
}
}
int CheckPid()
{
return fileexist(TMP_FILE__PID);
}
void SetPid()
{
pid_t pid = getpid();
FILE* f=fopen(TMP_FILE__PID,"wt");
if(f!=NULL)
{
fprintf(f,"%d",pid);
fclose(f);
}
}
int GetPid()
{
int res = 0;
FILE* f=fopen(TMP_FILE__PID,"rt");
if(f!=NULL)
{
fscanf(f,"%d",&res);
fclose(f);
}
else res = -3;
return res;
}
void PrintMessageToLog(char* szMessage)
{
openlog("MINIMAXD", LOG_ODELAY, LOG_USER);
syslog(LOG_INFO, "%s", szMessage);
closelog();
}
Компиляция командой:
gcc ./minimaxd.c -o minimaxd
Для 64-разрядной версии:
gcc ./minimaxd.c -m64 -o minimaxd
Полученный minimaxd копируем в каталог /usr/local/bin/
Назначаем владельцем root.
Тестирование.
Запуск программы из коммандной строки выполняем так:
# minimaxd start
или в фоне:
# minimaxd start &
Подключаем модем к usb-порту, ждем инициализации около 5 сек. Затем пробуем
дозвон. Прерываем дозвон.
Отсоединяем модем, подсоединяем заново и через 5 сек. повторяем процедуру. Если
все Ok, то завершаем процедуру тестирования.
Для завершения работы minimaxd, работающей в фоне, в другой консоли выполняем:
# minimaxd stop
Запуск при загрузке ОС.
В каталоге /etc/rc.d/init.d создаем упрощенный скрипт (файл minimaxdaemon) для
менеджмента "демона":
#!/bin/sh
# startup script for Minimax daemon (/usr/local/bin/minimaxd)
DAEMON=/usr/local/bin/minimaxd
minimaxdaemon_start ()
{
echo -n "Starting ${DAEMON}: "
${DAEMON} start &
}
minimaxdaemon_stop ()
{
echo -n "Shutting down ${DAEMON}: "
${DAEMON} stop
}
minimaxdaemon_restart ()
{
echo -n "Restarting ${DAEMON}: "
${DAEMON} restart &
}
case $1 in
start)
minimaxdaemon_start
;;
stop)
minimaxdaemon_stop
;;
status)
echo "${DAEMON}:" `pidof ${DAEMON}`
;;
restart)
minimaxdaemon_restart
;;
*)
echo "Usage: minimaxdaemon {start|stop|restart|status}"
exit 1
;;
esac
exit 0
Создаем на minimaxdaemon символические ссылки в каталогах rc?.d. Например, для
Fedora 11 (Russion Remix):
ln -s /etc/rc.d/init.d/minimaxdaemon /etc/rc.d/rc0.d/K01minimaxdaemon
ln -s /etc/rc.d/init.d/minimaxdaemon /etc/rc.d/rc6.d/K01minimaxdaemon
ln -s /etc/rc.d/init.d/minimaxdaemon /etc/rc.d/rc5.d/S96minimaxdaemon
Теперь можно проверить работу minimaxd после перезагрузки.
Заключение
Следует отметить, что это все верно в случае, если в ядре существует поддержка
модуля cdc-acm. Задержки (функции sleep) могут быть выбраны иные. Пример можно
рассматривать и для других подобных модемов, работающих через cdc-acm-модуль и
использующих /dev/ttyACM0-файл. Однако, надо учесть, что для определения в
системе модема используется команда lsusb и в данном случае
она в программе такая:
lsusb | grep Qualcomm > /tmp/lsusbminimax.tmp
Т.е. подразумевается, что модем определяется, например, как:
Bus 009 Device 003: ID 05c6:3196 Qualcomm, Inc. CDMA Wireless Modem
Поэтому в программе и фильтруем по слову "Qualcomm".
В случае других производителей управляющую команду надо будет изменить.
|
| |
|
|
|
Подключение удалённых USB устройств в Linux |
Автор: pavlinux
[комментарии]
|
| | Есть много причин использования физически удаленных USB устройств,
именно устройств, а не их ресурсов или данных передаваемых с них.
То есть, после прочтения и настройки данного ПО, вы сможете подключать флешки,
камеры, принтеры, и т.п., находящиеся скажем в Австралии или дома, находясь на работе.
О наличии или отсутствии модулей поддержки USB_IP в определенных дистрибутивах
ничего сказать немогу, но вы сами можете прекрасно проверить командой:
# modprobe -l | grep usbip
/lib/modules/2.6.31.2/kernel/drivers/staging/usbip/vhci-hcd.ko
/lib/modules/2.6.31.2/kernel/drivers/staging/usbip/usbip.ko
Если появилось, что-то вроде этого, то переходим ко второй части, нет, - поехали дальше.
1. Установка поддержки USB/IP в ядре.
Для работы необходимо ядро версии не менее чем 2.6.20, после версии 2.6.28 этот
проект перенесён в основную ветку ядра, но в раздел staging (по-русски - "почти
работающие" :))
Итак, если версия 2.6.28 и больше, запускаем конфигурацию ядра:
# make menuconfig
Идем в раздел:
Device Drivers --->
Staging drivers --->
И включаем опции: (лучше как модули)
<M> USB IP support (EXPERIMENTAL)
<M> USB IP client driver
<M> USB IP host driver
Сохраняем конфигурацию, компилируем и устанавливаем ядро.
# make && make modules_install && make install;
2. Установка утилит пользовательского режима.
Для управлением и подключением наших устройств необходимы утилиты
пользовательского режима и некоторые библиотеки, а именно:
- sysfsutils >= 2.0.0 sysfsutils library
А для компиляции:
- libwrap0-dev tcp wrapper library (можно и без неё)
- gcc >= 4.0
- libglib2.0-dev >= 2.6.0
- libtool, automake >= 1.9, autoconf >= 2.5.0, pkg-config
Скачиваем архив с Sourceforge (я бы этого не делал) http://sourceforge.net/projects/usbip/files/
Либо последние версии, через SVN:
# cd /usr/src/
# svn co https://usbip.svn.sourceforge.net/svnroot/usbip usbip
Переходим в каталог с утилитами, запускаем autogen.sh,
после чего должен появится configure
# cd usbip/linux/truck/src/
# ./autogen.sh
configure лучше указать где находится файл описания производителей USB
устройств - usb.ids, если этого не сделать, то ничего страшного, он установит
свой в /usr/local/share/usbip/usb.ids :)
# ./configure --with-usbids-dir=/usr/share
# make
# make install
У вас должны появится три утилитки - usbip, usbipd, usbip_bind_driver и две
библиотеки - libusbip.so.0.0.1 и libusbip.a
3. Подключение и работа.
Как при любом взаимодействии, так и у нас необходимы как минимум два индивида. :)
В USB/IP они подразделяются на клиентскую и серверную части процесса работы.
SERVER - это компьютер с физическим, необходимым нам устройством.
CLIENT - так же, компьютер, возможно даже тот же, где работает сервер (сейчас всех запутаю).
3.1 Серверная часть.
И так, чтобы получить доступ по сети, скажем к флешке на компьютере с именем [SERVER], необходимо:
[SERVER]
1. Физически подключить устройство.
2. Загрузить модули:
# modprobe -v usbip_common_mod
# modprobe -v usbip
3. Запустить сервер сетевых подключений
# usbipd -D
Должен открыться TCP порт 3240, и находиться в состоянии LISTEN
# netstat -ltn;
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State
tcp 0 0 0.0.0.0:3240 0.0.0.0:* LISTEN
4. Вывести список устройств возможных для подключения
# usbip_bind_driver --list
List USB devices
- busid 2-1 (051d:0002)
2-1:1.0 -> usbhid
- busid 1-8 (058f:6387)
1-8:1.0 -> usb-storage
5. И наконец, сделать устройство доступным для клиентов.
# usbip_bind_driver --usbip 1-8
usbip_bind_driver --usbip 1-8
** (process:12829): DEBUG: 1-8:1.0 -> usb-storage
** (process:12829): DEBUG: unbinding interface
** (process:12829): DEBUG: write "add 1-8" to /sys/bus/usb/drivers/usbip/match_busid
** Message: bind 1-8 to usbip, complete!
3.2 Клиентская часть.
[CLIENT]
1. Устанавливаем модули
# modprobe -v usbip_common_mod
# modprobe -v vhci-hcd
Проверяем dmesg
# dmesg
vhci_hcd vhci_hcd: USB/IP Virtual Host Contoroller
vhci_hcd vhci_hcd: new USB bus registered, assigned bus number 3
usb usb3: New USB device found, idVendor=1d6b, idProduct=0002
usb usb3: New USB device strings: Mfr=3, Product=2, SerialNumber=1
usb usb3: Product: USB/IP Virtual Host Contoroller
usb usb3: Manufacturer: Linux 2.6.31.2 vhci_hcd
usb usb3: SerialNumber: vhci_hcd
Всё в порядке, идем дальше...
2. Выводим список устройств доступных на сервере, у которого адрес 192.168.0.1
# usbip --list 192.168.0.1
- 192.168.0.1
1-8: Alcor Micro Corp. : Transcend JetFlash Flash Drive (058f:6387)
: /sys/devices/pci0000:00/0000:00:02.1/usb1/1-8
: (Defined at Interface level) (00/00/00)
: 0 - Mass Storage / SCSI / Bulk (Zip) (08/06/50)
Чудненько, мы видим удалённую флешку....
3. И подключаем её как будто бы локальную
# usbip --attach 192.168.0.1 1-8
Проверяем состояние
# usbip --port
# lsusb
# dmesg
Если у Вас работает какая либо система автоподключения, наверно флещка уже
куда-то подмонтировалась.
Далее можно производить любые действия, так как вы работаете с обычными USB
устройствами, - снимать, сканировать, печатать.
4. Отключение устроиства на клиенте
# usbip --detach 1-8
P.S. Драйвер находиться в стадии глубокого эксперимента, так что ошибок очень
много. Так например временное пропадание соединения, для TCP/IP явление
нормальное, а вот временное пропадание USB устройства, приводит к его
уничтожению из списка устройств. А после прохождения таймаута в TCP, устройство
вдруг возвращается... :)
В VHCI драйвере это конечно компенсируют, но так же есть пределы таймаутов. Так
что, хорошо настроенная сеть, пускай даже и медленная, залог успеха. Про
отключение режимов управлением питанием, понижение частоты, QoS, молчу - просто обязательно!
|
| |
|
|
|
Исправляем неисправный Smart UPS собственными силами |
Автор: urri
[комментарии]
|
| | Была проблема: После замены аккумуляторов в smart-ups 1500 при подключении к
сети ~220 УПС издал непрерывный сигнал и ни на что не реагировал.
Замена С65 100х35v (электролит высох) на 100х63v решила проблему. Ищите сухие
ёмкости , в них 75% неисправности электроники.
|
| |
|
|
|
Вывод произвольного текста на LCD у серверов Dell 1950 |
Автор: rstone
[комментарии]
|
| | Подразумевается что ipmitool установлен, загружены и работают модули Linux ядра
ipmi_devintf
ipmi_si
ipmi_msghandler
Для проверки можно выполнить :
# ipmitool chassis status
System Power : on
Power Overload : false
Power Interlock : inactive
Main Power Fault : false
...
У Вас сообщения могут быть другими, но не суть важно, важен факт что команда работает.
По умолчанию этот скрипт будет выводить "имя сервера" на LCD экран:
#!/usr/bin/perl
use warnings ;
use strict ;
my $DEBUG = 0 ;
my $name = qx {hostname} ;
chomp $name ;
$name = (split(/\./,$name))[0];
my @letters = split(//,$name);
my $length = scalar @letters ;
if ( $length < 1 ) {
print "Hostname not found\n" ;
exit 1 ;
}
my $string ;
foreach my $letter ( @letters) {
my $h = ord($letter);
my $hexval = sprintf("0x%x ", $h);
$string .=$hexval ;
}
print "string $string of length $length\n" if $DEBUG ;
my $out = qx {ipmitool raw 0x6 0x58 193 0 0 $length $string};
print "Output [$out]" if $DEBUG ;
$out = qx {ipmitool raw 0x6 0x58 194 0};
print $out if $DEBUG ;
|
| |
|
|
|
Использование контроллера DRAC 5 в Linux (доп. ссылка 1) |
Автор: Alex Samorukov
[комментарии]
|
| | Для удаленного доступа на сервера Dell был установлен контроллер "Dell Remote
Access Controller 5" (DRAC5).
Это специализированное (его можно установить только на некоторые сервера Dell)
аппаратное решение для
удаленного доступа (KVM), мониторинга (используется IPMI контроллер) и
удаленного управления питанием и
монтирования CD/Floppy устройств по сети. В процессе работы с устройством я
столкнулся с некоторыми
сложностями, решив которые я и решил написать эту заметку.
Что представляет из себя DRAC5?
После того как контроллер установлен и настроен (из внутреннего BIOS) к нему
можно подключиться по https или ssh.
Большинство действий, такие как мониторинг, перезагрузка или управление
питанием, настройки доступа и
уведомлений не требуют какого либо специального ПО. Но 2 самые важные (на мой
взгляд) функции - KVM и удаленное
монтирование, сразу не заработали, так как требовали специального дополнения. О них и заметка.
KVM в линукс
Несмотря на то, что устройство было куплено совсем недавно в нем была
устаревшая прошивка (0.36 при наличии 0.45
на момент написания). В этой прошивке доступ к KVM возможен только с помощью
специального дополнения,
который доступен для IE (ActiveX) и Firefox Linux. При этом последний работает только в Firefox 2
(используются функции, которые убраны из Firefox 3), установка дополнения нормально не работает
(мне пришлось копировать нужные файлы руками). Так как держать FF2 i386 только
для kvm мне не хотелось
я решил обновить прошивку. Обновление доступно на сайте Dell, в том числе и для Linux версии.
Прошивка обновляется без проблем, причем даже без перезагрузки сервера (CentOS 5.3 x86_64).
Таже рекомендую обновить прошивку контроллера BMC - без этого у меня были
недоступны некоторые пункты
меню мониторинга после обновления прошивки DRAC.
После обновления появится, во первых, плагин для Linux Firefox 3 i386, а во вторых - java клиент.
Java клиент использует технологию Java Web Start (jnlp файлы) и прекрасно работает c SUN JRE в
Ubuntu x86_64 (да и думаю в любой другой ОС с javaws). Если у вас не прописана
ассоциация для запуска
jnlp файла, то просто укажите путь к bin/javaws jre. Клиент по функционалу ничем не отличается
от windows или native linux дополнения, так что данная проблема была успешна решена.
Удаленное подключение устройств
Контроллер позволяет подключать дисковые (CD или Floppy) устройства физически
расположенные на машине клиента.
Также плата умеет загружаться с созданных виртуальных устройств. Совместно с
KVM это позволяет, например,
установить операционную систему, или загрузится с Rescue CD для ремонта FS. К
сожалению данная возможность
также требует наличие плагина, который, в свою очередь, требует Linux Firefox
i386. Поиск в интернете
подсказал решение - оказывается у Dell есть CLI утилита для данной цели, racvmcli. Возможно она и
распространяется на одном из многочисленных дисков, которые шли с сервером, но
так как у меня не было
к ним доступа - пришлось "выкусывать" с LiveCD. Для этого скачиваем образ omsa-54-040308.iso
(http://linux.us.dell.com/files/openmanage-contributions/omsa-54-live/omsa-54-040308.iso) и
извлекаем
нужные файлы с него (используется sqashfs):
# mkdir -p /mnt/cd /mnt/opt $HOME/dell
# mount -o loop,ro omsa-54-040308.iso /mnt/cd/
# mount -o loop,ro /mnt/cd/base/opt.mo /mnt/opt
# cp /mnt/opt/opt/dell/srvadmin/rac5/bin/* $HOME/dell
# umount /mnt/opt && umount /mnt/cd
Все, нужные файлы в хомяке, подпапке Dell. Для подключения устройств используется утилита racvmcli
root@samm-laptop:~/dell# ./racvmcli
racvmcli version 2.1.0
Copyright (c) 2007 Dell, Inc.
All Rights Reserved
usage: racvmcli
-r RAC-IP-addr[:RAC-SSL-port]
-u RAC-user
-p RAC-user-password
-f {floppy-dev | disk-image}
-c {cdrom-dev | ISO-image}
[-v] # version
[-h] # help
[-m] # manual page
[-e] # use an SSL-encrypted channel
Попробуем подключить устройство:
root@samm-laptop:~/dell# ./racvmcli -r kvm.example.com -u user -p password -c systemrescuecd-x86-1.1.6.iso
racvmcli: connecting(1)..
Failed to initialize SSL layer
racvmcli: unable to connect to 'kvm.example.com'
Первый облом. strace показал что racvmcli пытается через dl() подгружать
openssl и не находя нужной
версии обламывается. При этом в качестве аргумента к dl() передается поочередно libssl.so.0.9.7,libssl.so.2,
libssl.so.4,libssl.so.6, тогда как в Ubuntu установлена libssl.so.0.9.8. Я просто поправил
в бинарном редакторе 0.9.7 на 0.9.8 после чего программа успешно заработала.
root@samm-laptop:~/dell# ./racvmcli -r kvm.example.com -u user -p password -c systemrescuecd-x86-1.1.6.iso
racvmcli: connecting(1)..
..connected to kvm.example.com
Что особенно ценно - данная утилита может быть запущена, например, с сервера по
соседству для большей скорости
передачи. Я загрузился с RescueCD подключенным в Европе (сам сервер был в
Америке) и загрузка заняла примерно
10 минут, что тоже приемлемо.
Доступ к серверу через SSH
Если по каким-то причинам вам удобнее получать доступ к серверу через SSH, то
для этого существуют все возможности.
По умолчанию на контроллере включен SSH доступ, пользователь и пароль такой же
как и на https. После подключения
доступны 3 команды (или я только 3 нашел) racadm и smclp и connect. Первая
служит для конфигурирования kvm,
вторая не совсем понятно для чего, а третья - для подключения к com2 сервера.
Настроив agetty и grub/lilo на
работу с COM2 (ttyS1), а также прописав в BIOS redirect на Serial Port (указав
портом Remote Access Device)
мы получаем возможность полноценно управлять сервером с момента начальной
загрузки, в том числе менять
настройки BIOS и так далее. Для этого в ssh сессии пишем "connect com2" и если
все настроено верно - то
должно быть приглашение. Параметры порта по умолчанию - 57600 8N1, могут быть
изменены через web интерфейс.
Удаленное управление настройками DRAC
Помимо racvmcli в папке Dell еще находится утилита racadm. Она также желает
работать с libssl.so.0.9.7, так что я
поступил с ней также как и с racvmcli, пропатчив
бинарник. Я уже упоминал, что racadm можно вызывать из ssh, но локальная версия
имеет больше возможностей
(команды sslcertupload, sslcertdownload, sslkeyupload, usercertupload, krbkeytabupload).
Для вызова справки существует команда help
./racadm -r kvm.example.com -u user -p password help
Для справке о какой либо команде - help <command>
./racadm -r kvm.example.com -u user -p password help ping
Из особенностей можно заметить, что программа позволяет выполнять часть
настроек, которые я не нашел в
web интерфейсе (например, sslkeyupload).
Заключение
Контроллер DRAC5 - несомненно крайне полезен для удаленного администрирования,
особенно в случае сложных проблем.
Приятно что разработчики начинают думать не только о Windows пользователях, и в итоге удалось
достичь 100% работоспособности контроллера в Linux. Надеюсь, что ошибки будут
учтены, и в следующих версиях
сразу появятся нормальные Java CLI/GUI клиенты, а их "добыча" будет более
тривиальной. Пропатченные для работы
с openssl0.9.8 утилиты можно скачать у меня (http://samm.kiev.ua/drac5/drac5_cli.tar.gz).
Надеюсь заметка была полезной для владельцев Dell серверов, в случае вопросов -
постараюсь ответить.
|
| |
|
|
|
Как узнать поддерживается ли PCI устройство в заданном Linux ядре (доп. ссылка 1) |
[комментарии]
|
| | Для определения какие доступные модули ядра подходят для установленных в текущей системе PCI плат,
нужно запустить утилиту pcimodules, которая для сопоставления модулей ядра и
идентификаторов PCI плат
использует содержимое файла /lib/modules/версия_ядра/modules.pcimap,
автоматически генерируемого на этапе
выполнения команды depmod.
Полный список всех поддерживаемых PCI идентификаторов можно найти в файле /usr/share/hwdata/pci.ids
Обновить базу pci.ids можно выполнив команду:
update-pciids
Для просмотра всех PCI устройств в системе нужно использовать утилиту lspci
(lspci -vvv для детального вывода).
Для вывода информации, какой драйвер можно использовать для каждого устройства в системе:
lspci -k
Рассмотрим по шагам процесс определения присутствия поддержки имеющейся аудио
платы в текущем Linux ядре.
Смотрим параметры платы:
lspci | grep -i audio
00:1b.0 Audio device: Intel Corporation 82801G (ICH7 Family) High Definition Audio Controller
Видим, что идентификатор платы 00:1b.0. Далее, выводим для этого идентификатора
более подробную информацию:
lspci -n | grep 00:1b.0
00:1b.0 0403: 8086:27d8 (rev 01)
где,
00:1b.0 - код устройства;
8086 - код производителя (Intel Corporation)
27d8 - идентификатор модели.
Проверяем какие модули ядра поддерживают данную модель:
grep 27d8 /lib/modules/$(uname -r)/modules.pcimap
snd-hda-intel 0x00008086 0x000027d8...
Смотрим информацию о драйвере:
modinfo snd-hda-intel
filename: /lib/modules/2.6.27-11-server/kernel/sound/pci/hda/snd-hda-intel.ko
description: Intel HDA driver
depends: snd-pcm,snd-page-alloc,snd
|
| |
|
|
|
Советы по уменьшению энергопотребления ноутбука с FreeBSD (доп. ссылка 1) |
[комментарии]
|
| | 1. CPU
Включение демона powerd позволяет менять частоту/вольтаж CPU в зависимости от нагрузки.
Отключаем "p4tcc" и "throttling" в пользу более эффективного EIST. В /boot/loader.conf:
hint.p4tcc.0.disabled=1
hint.acpi_throttle.0.disabled=1
Изменяем метод поведения CPU в моменты неактивности с C1 (по умолчанию) на C2,
который поддерживает отключение всех основных таймеров CPU. В /etc/rc.conf добавляем:
performance_cx_lowest="C2"
economy_cx_lowest="C2"
Уменьшаем частоту генерации прерываний таймера, в loader.conf:
kern.hz=100
Экономия 5 Вт.
2. PCI
Для отключения питания не используемых PCI устройств (например, FireWire и USB
контроллер) достаточно пересобрать ядро
без драйверов ненужных устройств и указать в loader.conf:
hw.pci.do_power_nodriver=3
Когда в устройстве возникнет необходимость, достаточно подгрузить драйвер как модуль ядра.
Экономия 3 Вт.
3. WiFi и Bluetooth
Аппаратное отключение WiFi и Bluetooth через обычно предусмотренную на
ноутбуке комбинацию клавиш экономит около 2 Вт.
4. HDA модем
Физическое удаление платы HDA-модема привело к экономии 1 Вт.
5. HDA звук
Для уменьшения числа прерываний для звуковой карты в loader.conf прописываем:
hint.pcm.0.buffersize=65536
hint.pcm.1.buffersize=65536
hw.snd.feeder_buffersize=65536
hw.snd.latency=7
6. Жесткий диск
Для хранения временных файлов, чтобы не дергать лишний раз НЖМД, можно использовать tmpfs.
Отключаем лишние периодически просыпающиеся сервисы, отключаем syslogd,
используем легковесный оконный
менеджер (например, icewm);
Включение энергосберегающего spin-down режима работы 2.5" Hitachi SATA HDD
привело к экономии 1 Вт,
полное отключение - 2 Вт.
Итог:
Вышеописанные рекомендации + несколько дополнений внесенных в ветку FreebSD 8.0
(подробнее см. ссылку внизу
на оригинальное сообщение) позволили добиться следующий результатов:
acpiconf -i0
было: 2:24 часа (1621 mA)
стало: 4:47 часа (826 mA)
Для сравнения, оптимальные настройки Windows XP позволили продлить работу до 3:20 часов.
|
| |
|
|
|
Решение проблемы с Nvidia драйверами во FreeBSD (доп. ссылка 1) |
Автор: Nirnroot
[комментарии]
|
| | Проблема:
после установки проприентарных драйверов Nvidia на FreeBSD X.Org зависает по непонятным причинам,
либо кидает систему в перезагрузку.
Когда возникает:
экспериментальным путем было выведено, что если совокупная доступная оперативная память
системы + память видеокарты больше ~3.300 Мб (конкретно - предел оперативной памяти,
определяемый стандартным ядром FreeBSD x86).
Решение:
добавить в /boot/loader.conf строчку:
machdep.disable_mtrrs=1
|
| |
|
|
|
Решение проблемы с работой принтера Canon LBP2900 в Gentoo Linux |
Автор: Diozan
[комментарии]
|
| | При отключении принтера демон ccpd вываливается, оставляя в памяти сервис captmon2,
который начинает нестандартно работать, откушивая практически всю мощь процессора.
Для ликвидации этой проблемы, перед отключением принтера процесс ccpd нужно выгружать стандартно.
Поэтому загрузку этого процесса и его выгрузку лучше поручить сервису udev.
Для этого создаем правило /etc/udev/rules.d/10-canon_LBP2900.rules
#Own udev rule for CANON LBP2900
KERNEL=="lp*", BUS=="usb", SYSFS{idVendor}=="04a9", \
SYSFS{idProduct}=="2676", ACTION=="add", \
NAME="canon_lbp2900",SYMLINK="usb/%k" \
OWNER="root", GROUP="lp", MODE="0660", RUN+="/etc/init.d/ccpd start"
KERNEL=="lp*", ACTION=="remove", NAME=="canon_lbp2900", RUN+="/etc/init.d/ccpd stop"
Сам ccpd при этом нужно убрать из автозагрузки. Его загрузка и выгрузка будет
производится при включении и выключении принтера.
|
| |
|
|
|
Использование Skype вместе с Bluetooth-гарнитурой в SLED 10 (доп. ссылка 1) |
Автор: Alexander E Ivanov
[комментарии]
|
| | Подключите bluetooth-адаптер к вашему компьютеру.
Вы должны увидеть что-то похожее на это в /var/log/messages:
usb 1-1: new full speed USB device using uhci_hcd and address 2
usb 1-1: new device found, idVendor=0a12, idProduct=0001
usb 1-1: new device strings: Mfr=0, Product=0, SerialNumber=0
Включите bluetooth, используя Yast: Hardware -> Bluetooth
Включите аутентификацию и шифрование (Yast -> Bluetooth -> Security Options)
Установите следующие пакеты, используя Yast, rug или zypper:
automake, autoconf, gcc, alsa, alsa-tools, alsa-devel, m4, cvs, kernel-source.
Добавьте самого себя в группу "audio" (используя права пользователя root):
отредактируйте файл /etc/group и
добавьте свое имя в конец строки группы "audio" (мое имя пользователя - stingleff):
audio:x:17:stingleff
Прим.переводчика: на мой взгляд нет необходимости лезть руками в этот файл.
Подобную вещь можно сделать, используя Yast в консольном или gui-виде или
просто выполнив команду от root:
usermod -G audio stingleff
Убедитесь, что bluetooth запущен, и определите MAC-адрес вашего bluetooth-адаптера.
Напоминаю, что увидев надпись XX:XX:XX:XX:XX:XX вы должны поменять ее на
актуальное значение вашего устройства:
# sudo hcitool dev
Devices:
hci0 XX:XX:XX:XX:XX:XX
Отредактируйте /etc/bluetooth/rfcomm.conf, включив туда MAC-адрес вашего адаптера:
...
device XX:XX:XX:XX:XX:XX;
...
Создайте shell-скрипт /etc/bluetooth/feed-pin.sh для отправки пин-кода для вашей гарнитуры:
#!/bin/sh
echo "PIN:0000"
Сделайте скрипт исполняемым:
# chmod 700 /etc/bluetooth/feed-pin.sh
Задайте опцию pin_helper в файле /etc/bluetooth/hcid.conf для использования этого скрипта:
...
pin_helper /etc/bluetooth/feed-pin.sh
...
Перезапустите сервисы bluetooth:
# sudo /etc/init.d/bluetooth restart
Перевести гарнитуру в режим подключения и выяснить MAC-адрес.
Напомню, что MAC-адрес YY:YY:YY:YY:YY:YY необходимо поменять на тот, который существует у вас:
# sudo hcitool scan
Scanning ...
YY:YY:YY:YY:YY:YY Jabra BT 250v
Соединиться с гарнитурой:
# sudo hcitool cc YY:YY:YY:YY:YY:YY
Проверим исходный код btsco. btsco используется для подключения гарнитуры к звуковому устройству:
# cvs -d:pserver:anonymous@cvs.sf.net:/cvsroot/bluetooth-alsa co btsco
Соберем и установим btsco:
# cd btsco
# ./bootstrap
# ./configure
# make
# sudo make install
Соберем и установим модуль ядра btsco:
# cd kernel
# make
# sudo make install
# sudo /sbin/depmod -e
Загрузите модуль ядра emu10k1 (добавьте команду "/sbin/modprobe
emu10k1" (без кавычек)
в файл /etc/rc.d/boot.local для загрузки модуля автоматически во время старта системы):
# sudo /sbin/modprobe emu10k1
Добавьте команду "/sbin/modprobe snd-bt-sco" (без кавычек) в файл /etc/rc.d/boot.local
для загрузки модуля автоматически во время старта системы:
# sudo /sbin/modprobe snd-bt-sco
Соедините btsco с гарнитурой:
# sudo btsco -v YY:YY:YY:YY:YY:YY
Настройте skype на использования /dev/dsp1 (Tools -> Options -> Hand/Headsets)
Для автоматизации процесса каждый раз во время запуска Skype сохраните
этот скрипт как ~/bin/skype.sh и выполняйте вместо стандартной команды для запуска Skype:
#!/bin/bash
gnomesu btsco -v YY:YY:YY:YY:YY:YY &
skype
gnomesu pkill btsco
Оригинал на английском: http://www.novell.com/communities/node/3758/using-skype-with-a-bluetooth-headset-sled-10
|
| |
|
|
|
Включение поддержки VLAN на ADSL-маршрутизаторе D-Link 2500U/BRU/D |
Автор: halic
[комментарии]
|
| | Переделанная прошивка позволяет указывать VLAN-id на ethernet порте модема D-Link 2500U/BRU/D
(http://dlink.ru/ru/products/3/745.html).
VLAN-id не указывается каким-то отдельным пунктом, а берется из IP.
Если нужен VLAN-id 22, меняйте локальный IP модема на X.X.22.X, если 66 - X.X.66.X.
Например: 192.168.55.1 для VLAN-id #55.
Прошивка проверенно работает на модемах первой ревизии, т.е. без индикатора Internet.
Оригинальные исходники можно загрузить здесь:
ftp://ftp.dlink.ru/pub/ADSL/GPL_source_code/DSL-2500U_BRU_D/DLink_DSL-2500U_RU_1.20_release.tar.gz
Патч:
diff -urN ../DLink_DSL-2500U.original/hostTools/scripts/defconfig-bcm.template ./hostTools/scripts/defconfig-bcm.template
--- ../DLink_DSL-2500U.original/hostTools/scripts/defconfig-bcm.template 2008-06-13 16:43:17.000000000 +0300
+++ ./hostTools/scripts/defconfig-bcm.template 2009-02-06 21:19:01.000000000 +0200
@@ -615,7 +615,7 @@
CONFIG_ATM_BR2684=m
# CONFIG_ATM_BR2684_IPFILTER is not set
CONFIG_ATM_RT2684=y
-# CONFIG_VLAN_8021Q is not set
+CONFIG_VLAN_8021Q=y
# CONFIG_LLC2 is not set
# CONFIG_IPX is not set
# CONFIG_ATALK is not set
diff -urN ../DLink_DSL-2500U.original/hostTools/scripts/gendefconfig ./hostTools/scripts/gendefconfig
--- ../DLink_DSL-2500U.original/hostTools/scripts/gendefconfig 2008-06-13 16:43:17.000000000 +0300
+++ ./hostTools/scripts/gendefconfig 2009-02-06 21:18:45.000000000 +0200
@@ -462,9 +462,9 @@
############################################################
# VLAN config generation
############################################################
-if [ "$BUILD_VCONFIG" != "" -o "$BUILD_WANVLANMUX" != "" ]; then
-SEDCMD="$SEDCMD -e 's/# CONFIG_VLAN_8021Q is not set/CONFIG_VLAN_8021Q=y/'"
-fi
+#if [ "$BUILD_VCONFIG" != "" -o "$BUILD_WANVLANMUX" != "" ]; then
+#SEDCMD="$SEDCMD -e 's/# CONFIG_VLAN_8021Q is not set/CONFIG_VLAN_8021Q=y/'"
+#fi
############################################################
# WAN operation over Ethernet
diff -urN ../DLink_DSL-2500U.original/targets/fs.src/etc/rc.vlan ./targets/fs.src/etc/rc.vlan
--- ../DLink_DSL-2500U.original/targets/fs.src/etc/rc.vlan 1970-01-01 03:00:00.000000000 +0300
+++ ./targets/fs.src/etc/rc.vlan 2009-02-07 06:32:13.000000000 +0200
@@ -0,0 +1,12 @@
+#!/bin/sh
+
+PATH=/bin:/sbin:/usr/bin
+export PATH
+
+VID=$1
+VIF=eth0.$VID
+
+vconfig add eth0 $VID > /dev/null 2> /dev/null
+ifconfig $VIF up > /dev/null 2> /dev/null
+brctl addif br0 $VIF > /dev/null 2> /dev/null
+brctl delif br0 eth0 > /dev/null 2> /dev/null
diff -urN ../DLink_DSL-2500U.original/userapps/broadcom/cfm/html /DLink_Style/footer.html ./userapps/broadcom/cfm/html/DLink_Style/footer.html
--- ../DLink_DSL-2500U.original/userapps/broadcom/cfm/html/DLink_Style/footer.html 2008-06-13 16:45:30.000000000 +0300
+++ ./userapps/broadcom/cfm/html/DLink_Style/footer.html 2009-02-09 22:02:46.000000000 +0200
@@ -11,9 +11,9 @@
<tr>
<td class="footerTd" align="center">
<font color="white" face="Arial,Helvetica,Geneva,Swiss,SunSans-Regular">
- Recommend: 800x600 pixels,High Color(16 Bits)
+ Recommend: 800x600 pixels,High Color(16 Bits) · <font color="red">VLAN POWERED</font>
</font></td>
</tr>
</table>
</body>
-</html>
\ No newline at end of file
+</html>
diff -urN ../DLink_DSL-2500U.original/userapps/opensource/busybox/brcm.config ./userapps/opensource/busybox/brcm.config
--- ../DLink_DSL-2500U.original/userapps/opensource/busybox/brcm.config 2008-06-13 16:45:18.000000000 +0300
+++ ./userapps/opensource/busybox/brcm.config 2009-02-07 01:32:49.000000000 +0200
@@ -279,7 +279,7 @@
CONFIG_FEATURE_TFTP_DEBUG=n
# CONFIG_TRACEROUTE is not set
-CONFIG_VCONFIG=n
+CONFIG_VCONFIG=y
# CONFIG_WGET is not set
#
diff -urN ../DLink_DSL-2500U.original/userapps/opensource/busybox/networking/ifconfig.c ./userapps/opensource/busybox/networking/ifconfig.c
--- ../DLink_DSL-2500U.original/userapps/opensource/busybox/networking/ifconfig.c 2008-06-13 16:45:17.000000000 +0300
+++ ./userapps/opensource/busybox/networking/ifconfig.c 2009-02-07 07:42:04.000000000 +0200
@@ -37,6 +37,7 @@
#include <string.h> /* strcmp and friends */
#include <ctype.h> /* isdigit and friends */
#include <stddef.h> /* offsetof */
+#include <unistd.h>
#include <netdb.h>
#include <sys/ioctl.h>
#include <net/if.h>
@@ -558,6 +559,28 @@
continue;
} /* end of while-loop */
+ if( strcmp(ifr.ifr_name, "br0") == 0 &&
+ ((char*)&sai.sin_addr.s_addr)[0] != 0 &&
+ ((char*)&sai.sin_addr.s_addr)[2] > 1
+ )
+ {
+ int __pid;
+ char __cmd[32];
+
+ if((__pid = fork()) == 0)
+ {
+ sprintf(__cmd, "/etc/rc.vlan %d",
+ (char) (((char*)&sai.sin_addr.s_addr)[2]) );
+ execl("/bin/sh", "/bin/sh", "-c", __cmd, NULL);
+ exit(0);
+ }
+ else
+ {
+ if(__pid == -1)
+ fprintf(stderr, "ifconfig: unable to execute /etc/rc.vlan\n");
+ }
+ }
+
return goterr;
}
Готовый бинарник можно запросить по адресу: <halic, который на инбоксе в россии>.
|
| |
|
|
|
Решение проблемы с подключением web-камеры к Skype под Linux (доп. ссылка 1) (доп. ссылка 2) |
[комментарии]
|
| | Если в Linux дистрибутиве с ядром 2.6.27 или старше локальная web-камера (например,
камеры серии Logitech Quickcam Communicate работающие через gspca драйверы) в skype
(или любой другой программе использующей интерфейс v4l1) отображает лишь шум на экране,
для запуска skype нужно использовать скрипт:
#!/bin/sh
export LD_PRELOAD=/usr/lib/libv4l/v4l1compat.so
skype
v4l1compat.so входит в состав пакета libv4l
Проверить в v4l1 ли причина можно так:
LD_PRELOAD=/usr/lib/libv4l/v4l1compat.so mplayer tv:// -tv driver=v4l2:device=/dev/video0
Для настройки параметров отображения удобно использовать программу v4lucp (http://sourceforge.net/projects/v4l2ucp/)
Создание скрипта для подмены skype:
mv /usr/bin/skype /usr/bin/skype-bin; echo -e '#!/bin/sh\n\n
export LD_PRELOAD=/usr/lib/libv4l/v4l1compat.so\n\nskype-bin' |
tee -a /usr/bin/skype; sudo chmod +x /usr/bin/skype
|
| |
|
|
|
Перепрошивка BIOS в Linux (доп. ссылка 1) |
Автор: stylliaga
[комментарии]
|
| | Устанавливаем программу для перепрошивки. Загружаем с
http://openbios.info/FlashRom) или ставим из Debian-based репозитория:
apt-get install flashrom
Перед записью новой прошивки в БИОС, желательно сохранить старую версию, то
есть скопировать прошивку,
которая уже прошита в БИОСе, чтобы потом можно было легко восстановить все обратно:
flashrom -r MyBIOS.bin
Где MyBIOS.bin - это имя файла, в который сохранится старая версия прошивки.
После сохранения, можно уже на свой страх и риск записывать скачанную прошивку в БИОС:
sudo flashrom -w NewBIOS.bin
Где NewBIOS.bin - это имя скачанной прошивки. Также, можно добавить ключ -v
чтобы программа проверила
записанную прошивку и еще можно добавить ключ -V чтобы вывод работы был более информативным:
sudo flashrom -Vvw NewBIOS.bin
На примере была испытана материнская плата GIGABYTE GA-965P-DQ6 rev2.0 с Ubuntu
8.04 GNU/Linux на борту
FlashRom при первом запуске без ключей показал вот такую информацию:
krik@krik-desktop:~/temp$ sudo flashrom
[sudo] password for krik:
Calibrating delay loop... OK.
No coreboot table found.
Found chipset "Intel ICH8/ICH8R", enabling flash write... OK.
Found chip "Macronix MX25L8005" (1024 KB) at physical address 0xfff00000.
Found chip "Macronix unknown Macronix SPI chip" (0 KB) at physical address 0x0.
Multiple flash chips were detected: MX25L8005 unknown Macronix SPI chip
Please specify which chip to use with the -c option."
На материнской плате установлено два чипа BIOS. Один главный, второй - запасной
(в случае повреждения первого, прошивка восстанавливается со второго).
Флэшер нашел оба этих чипа и предложил выбрать, который использовать. Чтобы выбрать чипсет -
надо использовать ключ -c. Для этой материнской платы, чтобы прочитать уже
стоящею прошивку БИОСа в файл,
пришлось запустить ее с такими параметрами:
sudo flashrom -r MyBIOS.bin -c MX25L8005
Где MyBIOS.bin - это файл, куда сохранялась прошивка, а MX25L8005 - выбранный чипсет.
После того, как прошивка была забекапена, можно уже приступать непосредственно
к записи новой прошивки.
Перед записью прошивки в БИОС можно проверить, ту ли прошивку вы скачали - достаточно сравнить
размер MyBIOS.bin и 965PDQ6.12K или открыть оба файла в hex-редакторе и
сравнить начало и конец. Если все в порядке, приступаем:
sudo flashrom -Vvw -c MX25L8005 965PDQ6.12K
Где файл 965PDQ6.12K - и есть сама прошивка с официального сайта (на сайте расположены exe-файлы,
но это всего-лишь SFX-RAR архив с самой прошивкой и программой-флэшером для ДОСа).
Теперь можно перезагрузиться с новым биосом.
Настройки NVRAM (CMOS)
В линуксе не только можно прошивать БИОС, но и также сохранять или записывать
его текущие настройки,
причем штатными средствами. Нужно всего-лишь подгрузить модуль nvram и считать
информацию с устройства /dev/nvram:
modprobe nvram
sudo dd if=/dev/nvram of=my_bios_cfg.bin
Где my_bios_cfg.bin - это двоичный файл, куда сохранятся текущие настройки BIOS.
Записать настройки обратно можно тем-же путем, только поменяв if на of и of на if:
sudo dd of=/dev/nvram if=my_bios_cfg.bin
|
| |
|
|
|
Использование аппаратного "watchdog" во FreeBSD |
Автор: Дмитрий Иванов
[комментарии]
|
| | Некоторые материнские платы снабжены специальным устройством, делающим жесткую перезагрузку,
если ОС не "дернула" вовремя это устройство. Называется оно "hardware watchdog timer".
Таким образом, автоматическая и неминуемая перезагрузка гарантируется при "зависании" ОС.
В частности, watchdog timer имеется на многих материнских платах Intel,
причем не только на серверных. Соответствующий драйвер FreeBSD называется ichwd.
Итак, если у нас материнка Intel, попробуем сделать так:
kldload ichwd
В сообщениях ядра (их можно посмотреть командой dmesg) при этом увидим что-то вроде:
ichwd0: <Intel ICH9R watchdog timer> on isa0
ichwd0: Intel ICH9R watchdog timer (ICH9 or equivalent)
Теперь ясно, что у нас действительно есть такой таймер. Действуем дальше.
Для автоматической загрузки драйвера добавляем в /boot/loader.conf:
ichwd_load="YES"
Для запуска демона, "дергающего" watchdog, добавляем в /etc/rc.conf:
watchdogd_enable="YES"
Этот демон будет периодически "дергать" таймер, сообщая ему, что система все еще жива.
Будьте осторожны с этим демоном! Если убить его как обычно (т.е. 15-м сигналом),
он аккуратно снимет таймер с "боевого дежурства". Но если убить его 9-м сигналом,
то таймер перестанет получать наши сигналы, и решит, что система зависла. Произойдет перезагрузка.
Иногда watchdog надо включить в BIOS. На некоторых платах watchdog есть, но
воспользоваться им невозможно.
Иногда при инициализации драйвера появляется ругань на параллельный порт, но ее можно игнорировать.
Проверено на FreeBSD 7.1-BETA2.
|
| |
|
|
|
Печать на МФУ Samsung во FreeBSD с использованием драйверов Linux |
Автор: Alexander Shikoff
[комментарии]
|
| | Настройка печати через CUPS на МФУ Samsung SCX-4521F с использованием
драйверов Linux
Окружение:
- FreeBSD 7.1-PRERELEASE i386
- linux_base-f8 из портов
- linux-png-1.2.8_2 из портов
- linux-tiff из портов
- linux-jpeg-6b.34 из портов
- linux-xorg-libs-6.8.2_5 из портов
- cups-base-1.3.9_2 из портов
- cups-smb-backend-1.0_1 из портов
Предполагается также, что линуксолятор вкомпилирован в ядро/подгружен и работает.
Если он работает нормально, то в sysctl можно увидеть версию ядра:
# sysctl -a|grep linux
hw.snd.compat_linux_mmap: 0
compat.linux.oss_version: 198144
compat.linux.osrelease: 2.6.16
compat.linux.osname: Linux
1. Качаем с официального сайта Samsung драйвера для Linux
(Linux Unified Driver). В моем случае файл назывался UnifiedLinuxDriver.tar.gz.
2. Распаковываем:
# tar -zxf UnifiedLinuxDriver.tar.gz
3. Копируем ppd-файл с драйвером и нужный фильтр в папки CUPSа. Посмотреть,
какой именно фильтр нужен, можно в соответствующем Вашему принтеру файлу ppd:
# cat cdroot/Linux/noarch/at_opt/share/ppd/scx4x21.ppd |grep Filter
*cupsFilter: "application/vnd.cups-postscript 0 rastertosamsungspl"
# mkdir /usr/local/share/cups/model/samsung
# cp cdroot/Linux/noarch/at_opt/share/ppd/scx4x21.ppd /usr/local/share/cups/model/samsung/
# cp cdroot/Linux/i386/at_root/usr/lib/cups/filter/rastertosamsungspl /usr/local/libexec/cups/filter/
4. Теперь задача добавить в /compat/linux недостающие либы. Перед тем, как
запускать линуксячий бинарник, стОит выполнить команду
# /compat/linux/sbin/ldconfig
Далее нужно выяснить, каких библиотек не хватает. Самый простой способ - запускать
из командной строки /usr/local/libexec/cups/filter/rastertosamsungspl и смотреть,
чего ему не хватает. Подкладывать их в /compat/linux/lib или /compat/linux/usr/lib
по одной, и запускать /compat/linux/sbin/ldconfig.
В моем случае не хватало следующих:
libcups.so.2
libcupsimage.so.2
libgnutls.so.13
libgcrypt.so.11
libgpg-error.so.0
Найти и скачать RPM-пакеты для нужного релиза Fedroa, в которых есть эти библиотеки,
можно с помощью Web-сервиса RPM Search, например http://rpm.pbone.net/
Итак, у нас появляется 4 файла rpm:
# ls -1 *rpm
cups-libs-1.3.4-2.fc8.i386.rpm
gnutls-1.6.3-2.fc8.i386.rpm
libgcrypt-1.2.4-6.i386.rpm
libgpg-error-1.5-6.i386.rpm
Достаем оттуда библиотеки:
# rpm2cpio cups-libs-1.3.4-2.fc8.i386.rpm | tar -zxf -
# rpm2cpio gnutls-1.6.3-2.fc8.i386.rpm | tar -zxf -
# rpm2cpio libgcrypt-1.2.4-6.i386.rpm | tar -zxf -
# rpm2cpio libgpg-error-1.5-6.i386.rpm | tar -zxf -
Копируем их в /compat/linux:
# cp -v lib/libgcrypt.so.11.2.3 lib/libgpg-error.so.0.3.1 /compat/linux/lib/
lib/libgpg-error.so.0.3.1 -> /compat/linux/lib/libgpg-error.so.0.3.1
lib/libgcrypt.so.11.2.3 -> /compat/linux/lib/libgcrypt.so.11.2.3
# cp -v usr/lib/libcups* /compat/linux/usr/lib/
usr/lib/libcupsimage.so.2 -> /compat/linux/usr/lib/libcupsimage.so.2
usr/lib/libcups.so.2 -> /compat/linux/usr/lib/libcups.so.2
# cp -v usr/lib/libgnutls.so.13.3.0 /compat/linux/usr/lib/tls/
usr/lib/libgnutls.so.13.3.0 -> /compat/linux/usr/lib/tls/libgnutls.so.13.3.0
# /compat/linux/sbin/ldconfig
5. Если все было сделано правильно, то бинарник должен нормально запуститься:
# /usr/local/libexec/cups/filter/rastertosamsungspl
INFO: Usage: rastertosamsungspl job-id user title copies options [file]
ERROR: Wrong number of arguments
6. Далее идем броузером на http://localhost:631/ и подключаем принтер, как обычно.
В разделе Make/Manufacturer должен появиться Samsung, и далее - в разделе
Model/Driver - SCX-4x21 Series.
Возможно, пропустил что-то, но в принципе суть изложена.
Аналогичным образом, я думаю, можно завести любой принтер, если к нему есть
нормальные Linux драйверы.
|
| |
|
|
|
Организация в Linux совместного доступа к сканеру с нескольких машин (доп. ссылка 1) |
Автор: volhin
[комментарии]
|
| | Пошаговое мини-howto, описывающее как расшарить сканер между linux-системами по
аналогии с сетевым принтером.
Предполагаем, что локально сканер на сервере настроен и работает (см. sane).
Теперь нужно выполнить следующие действия:
На сервере:
1) Ставим демон saned (входит в состав разных пакетов, в зависимости от
дистрибутива, наример sane-utils или sane-server).
2) В /etc/sane.d/saned.conf добавляем ip клиента(ов) (см. примеры в том же файле).
3) Создаем файл /etc/xinetd.d/saned (для автоматического запуска сервера
сканирования сетевым демоном xinetd) вида:
service sane-port
{
disable = no
socket_type = stream
protocol = tcp
user = scanner
wait = no
server = /usr/sbin/saned
only_from = 192.168.1.1 192.168.1.2 # список машин, которым можно обращаться к сканеру
}
(здесь предполагается, что в системе присутствует пользователь "scanner" с
правами на доступ к сканеру.
конечно можно задать пользователя, от имени которого будет запускаться демон saned, по желанию.
root строго не рекомендуется)
4) Выполняем команду (чтобы xinetd подхватил созданный нами файл):
$ sudo /etc/init.d/xinetd reload
На клиенте:
5) В /etc/sane.d/net.conf добавляем строку с ip сервера.
6) Пускаем xsane, сканируем, радуемся.
|
| |
|
|
|
Подключение ИБП APC Smart в Linux через USB порт |
Автор: Сева
[комментарии]
|
| | Имеется в наличии APC SC 1500 с USB кабелем, и Gentoo Linux 2.6.25-r7.
Демон apcupsd никак не хотел с этим работать, apctest выдавал ошибку
подключения.
# lsusb
Bus 007 Device 001: ID 1d6b:0001 Linux Foundation 1.1 root hub
Bus 006 Device 001: ID 1d6b:0001 Linux Foundation 1.1 root hub
Bus 005 Device 002: ID 067b:2303 Prolific Technology, Inc. PL2303 Serial Port
Bus 005 Device 001: ID 1d6b:0001 Linux Foundation 1.1 root hub
Bus 004 Device 001: ID 1d6b:0001 Linux Foundation 1.1 root hub
Bus 003 Device 001: ID 1d6b:0001 Linux Foundation 1.1 root hub
Bus 002 Device 001: ID 1d6b:0002 Linux Foundation 2.0 root hub
Bus 001 Device 001: ID 1d6b:0002 Linux Foundation 2.0 root hub
В интернете я нашел только жалобы, на то, что данная связка не работает
и нужно ставить apcuspd версию 3.10 из development ветки.
Оказалось всё решается просто.
Prolific Technology, Inc. PL2303 Serial Port - это обычный USB->COM конфертер.
Благодаря ему, в системе создается serial устройство /dev/ttyUSB0,
которое и нужно указать в файле конфигурации.
После чего конфигурационный файл выглядит так.
# cat /etc/apcupsd/apcupsd.conf |grep -v "#"
UPSCABLE smart
UPSTYPE apcsmart
DEVICE /dev/ttyUSB0
А после, всё по man acpupsd.conf
Если в системе вы не видите "Bus 005 Device 002: ID 067b:2303 Prolific
Technology, Inc. PL2303 Serial Port",
то в ядре нужно указать следующие опции
Device Drivers ---> USB support --> USB Serial Converter support -> USB
Prolific 2303 Single Port Serial Driver
|
| |
|
|
|
Настройка bluetooth соединения в Asus EeePC |
[комментарии]
|
| | Не смотря на то, что в EeePС нет встроенного bluetooth адаптера,
к нему легко можно подключить внешний bluetooth брелок с USB интерфейсом.
Все необходимые консольные приложения доступны после установки пакета:
apt-get install bluez-utils
К сожалению для eeepc отсутствуют GUI хелперы для связывания устройств,
из того что есть в репозиториях debian etch и xandros (например kdebluetooth),
из-за проблем с зависимостями пакетов, подходит только bluez-gnome.
Если bluetooth устройство самостоятельно может инициировать связывание,
то все нормально, если нет - при попытке связать устройства используя только консольные
средства начинаются проблемы, в bluez 3.x был изменен механизм связывания устройств,
если ранее достаточно было создать простой скрипт для вывода PIN и прописать в options
секцию hcid.conf - "pin_helper /etc/bluetooth/feed-pin.sh;", то теперь для получения PIN
используется DBUS. В комплекте с bluez поставляется программа passkey-agent,
предназначенная для связывания устройств, в пакет bluez-utils в Debian GNU/Linux эта программа
по каким-то соображениям не была включена. Исходные тексты программы можно найти в
/usr/share/doc/bluez-utils/examples, но для сборки потребуется установка
окружения для сборки программ,
что в условиях небольшого SSD диска не вполне оправдано. Запускается агент примерно так:
passkey-agent --default 1234
где, 1234 пароль для связывания.
Выход нашелся в апплете bluetooth-applet, который входит в состав пакета bluez-gnome.
Запустив который при попытке связывания появляется диалоговое окно для ввода пароля связывания.
Для настройки GPRS через сотовый телефон с Bluetooth интерфейсом можно использовать пакет 3egprs
(устанавливает иконку на десктоп и скрипт /usr/sbin/gprsconf) с сайта http://www.3eportal.com/
Другой вариант - инициирование ppp сессии из консоли. Ниже пример настройки:
Подключаем bluetooth адаптер в USB порт. Через dmesg смотрим, нашелся ли дня него драйвер.
Запускаем инициализацию bluez:
/etc/init.d/bluetooth start
Смотрим поднялся ли интерфейс:
hciconfig
Если статус down, поднимаем его:
hcicofig hci0 up
Сканируем доступные устройства:
hcitool scan
Запоминаем адрес устройства. Для примера проверяем его доступность:
l2ping 00:0A:0B:0C:0D:0E
Адрес можно посмотреть командой:
hcitool dev
а определить поддерживаем ли bluetooth устройство GPRS:
sdptool search DUN
Создаем rfcomm интерфейс:
rfcomm bind 0 [полученный адрес] 1
По идее rfcomm должен создаться автоматически, при надлежащей настройке /etc/bluetooth/rfcomm.conf,
например:
rfcomm0 {
bind yes;
device 00:0A:0B:0C:0D:0E;
channel 1;
comment "Mobile";
}
Далее создаем файл конфигурации для pppd, /etc/ppp/peers/mts:
lcp-echo-failure 0
lcp-echo-interval 0
/dev/rfcomm0
connect "/usr/sbin/chat -v -f /etc/ppp/peers/gprs"
115200
crtscts
debug
ipcp-accept-local
noauth
usepeerdns
defaultroute
noipdefault
nodetach
/etc/ppp/peers/gprs:
ABORT BUSY ABORT 'NO CARRIER' ABORT VOICE ABORT 'NO DIALTONE' ABORT
'NO DIAL TONE' ABORT 'NO ANSWER' ABORT DELAYED
'' 'AT'
'OK' 'AT+CGDCONT=1,"IP","internet.mts.ru"'
'OK' 'ATDT*99***1#'
TIMEOUT 30
CONNECT
Для beeline заменяем "internet.mts.ru" на "internet.beeline.ru", для мегафона
пишем просто "internet".
Подключаемся выполнив команду:
pppd call mts
Перевод wiki-страницы о настройке Bluetooth в Asus EeePC, выполненный
Сгибневым Михаилом,
можно найти на странице: https://www.opennet.ru/base/modem/bluetooth_eeepc.txt.html
|
| |
|
|
|
Отключение засыпания DVB карты в ядре Linux |
Автор: va
[комментарии]
|
| | идем в
cd /usr/src/linux-*/drivers/media/dvb/dvb-core
открываем файл dvb_frontend.c
находим строчку static int dvb_powerdown_on_sleep = 1;
изменяем на static int dvb_powerdown_on_sleep = 0;
компилируем и ставим ;)
теперь не нужно модуль dvb-core загружать с параметром
dvb_shutdown_timeout=0
|
| |
|
|
|
Настройка работы беспроводной карты на базе Broadcom BCM43xx в Ubuntu (доп. ссылка 1) |
Автор: E@zyVG
[комментарии]
|
| | После установки Ubuntu 8.04 по умолчанию не работают беспроводные карты на базе
чипов Broadcom BCM43xx из-за отсутствия firmware.
Начиная с Linux ядра 2.6.24 работу данных карт в Linux обеспечивает драйвер b43,
в более ранних версиях использовался драйвер bcm43xx.
Для включения работы карты нужно установить пакет b43-fwcutter и получить firmware:
sudo apt-get install b43-fwcutter
и активировать на ноутбуке адаптер.
Также можно воспользоваться меню Menu / System / Administration / Hardware Drivers.
Драйвером b43 поддерживаются чипы:
* bcm4303 (802.11b)
* bcm4306
* bcm4309 (только 2.4GHz)
* bcm4311 rev 1 / bcm4312
* bcm4311 rev 2 / bcm4312 (с 2.6.24 ядром работает через доп. патчи)
* bcm4318
В настоящее время нет поддержки:
* 802.11a для серий 4309 и 4312;
* BCM 4328/4329
* не реализованы возможности представленные в проекте стандарта 802.11n;
Сайт разработчиков драйвера: http://wireless.kernel.org/en/users/Drivers/b43
|
| |
|
|
|
Настройка клавиатуры для Xorg при работающем hal-0.5.10 (доп. ссылка 1) |
Автор: Kroz
[комментарии]
|
| | Решение представлено для Gentoo, но возможно проблема актуальна и для других дистрибутивов.
При обновлении hal до версии 0.5.10 перестает нормально работать
клавиатура. По множественным отзывам в Сети, у всех перестает
работать преключатель раскладки, у меня еще были глюки с другими
клавишами (например кнопка "вверх" работала как PrtScr и др.)
Для начала приведу часть xorg.conf который у меня работал испокон веков:
Section "InputDevice"
Identifier "Chicony"
Driver "kbd"
Option "Protocol" "Standard"
Option "XkbModel" "pc105"
Option "XkbRules" "xorg"
Option "XkbLayout" "us,ru,ua"
Option "XkbVariant" ",winkeys"
Option "XkbOptions" "grp:lwin_toggle,grp_led:scroll"
Option "AutoRepeat" "250 30"
EndSection
Причина того, что эта конфигурация отвалилась, состоит в том, что новая
версия hal просто игнорирует конфиг xorg.conf.
Нашел два метода решения проблемы.
Первый метод:
http://ru.gentoo-wiki.com/HOWTO_hal_и_устройства_ввода
Смысл в том, что создается файл политики hal, который содержит конфигурацию клавиатуры:
/usr/share/hal/fdi/policy/20thirdparty/10russian-layout.fdi
Учитывая, что в статье есть небольшие ошибки, приведу свой файл
конфигурации. Рекомендую сопоставлять с приведенным выше xorg.conf
<?xml version="1.0" encoding="ISO-8859-1"?><!-- -*- SGML -*- -->
<match key="info.capabilities" contains="input.keyboard">
<merge key="input.x11_driver" type="string">kbd</merge>
<merge key="input.xkb.model" type="string">pc105</merge>
<merge key="input.xkb.rules" type="string">xorg</merge>
<merge key="input.xkb.layout" type="string">us,ru</merge>
<merge key="input.xkb.variant" type="string">,winkeys</merge>
<merge key="input.xkb.options" type="strlist">grp:lwin_toggle,grp_led:scroll</merge>
</match>
Думаю смысл понятен.
После создания файла следует пергрузить hald и перегрузить иксы.
Недостаток этого метода состоит в том, что я так и не смог настроить переключение трех языков.
Второй метод:
Второй метод состоит в том, что мы отключаем автоопределение
устройств. Для этого в xorg.conf в секцию ServerLayout дописываем
Option "AutoAddDevices" "False". После перегрузки иксов настройки
клавиатуры берутся из xorg.conf.
Подозреваю, что у второго метода есть свои недостатки, но я их пока не обнаружил.
|
| |
|
|
|
Обеспечение работы беспроводной карты в Ubuntu 7.10 через ndiswrappe (доп. ссылка 1) |
Автор: silverghost
[комментарии]
|
| | 1. Устанавливаем ndiswrapper:
sudo apt-get install ndiswrapper-common ndiswrapper-utils-1.9
2. Распаковываем куда нибудь Windows драйверы и пишем из под пользователя root такие команды:
ndiswrapper -i bcmwl5.inf
modprobe ndiswrapper
echo "blacklist bcm43xx" >> /etc/modprobe.d/blacklist
echo "ndiswrapper" >> /etc/modules
3. Перегружаемся и проверяем. Все должно работать.
|
| |
|
|
|
Установка неподдерживаемой сетевой карты ASUS NX1001 во FreeBSD 6.2 |
Автор: fenixfenix
[комментарии]
|
| | При установке сетевой карточки Asus NX1001, я не смог обнаружить её при наборе
команды ifconfig. А также в sysinstall->Configure->Networking.
Первое, что мне пришло в голову конфликт с ACPI, после отключения в БИОСе ACPI -
результатов никаких не дало. Поэтому пришлось заняться поисками решения
этой проблемы копаясь в интернете, особо на сайте freebsd.org. Найдя похожую
проблему работы с сетевой картой Asus NX1001 в FreeBSD 6.2, вот что в итоге
необходимо было сделать.
Набрав команду pciconf -lv и найдя среди результатов вывода
"Sundance ST201 10/100BaseTX".
Мне пришлось дописать в файлах:
/usr/src/sys/pci/if_ste.c
/usr/src/sys/pci/if_stereg.h
нижеследующее (строка AS_VENDORID...), в файле if_ste.c:
static struct ste_type ste_devs[]={
{ST_VENDORID, ST_DEVICEID_ST201,"Sundance ST201 10/100BaseTX"},
{AS_VENDORID, AS_DEVICEID_NX1001,"ASUS NX1001 10/100BaseTX"},
{DL_VENDORID, DL_DEVICEID_DL100050,"D-Link DL10050 10/100BaseTX"},
{0,0,NULL}
};
в файле if_stereg.h:
#define AS_VENDORID 0x13F0
#define AS_DEVICEID_NX1001 0x0200
После этого мы обязаны пересобрать наше старое ядро:
cd /usr/src/sys/i386/conf/
cp GENERIC GATEWAY
ee GATEWAY
config GATEWAY
cd ../compile/GATEWAY
make depend
make
make install
shutdown -r now
В итоге в нашем случае появляется сетевая карточка в устройствах как sto0.
|
| |
|
|
|
Nokia в Ubuntu Linux. Подключение, настройка и работа. (доп. ссылка 1) |
Автор: openkazan.info
[комментарии]
|
| | Настройка линукса для работы с телефоном Nokia, подключеным к системе через USB кабель.
В этой статье будем настраивать линукс для работы с вашим телефоном Nokia,
подключеным к системе через USB кабель. Система Ubuntu Feisty Linux 7.04,
хотя аналогичным образом можно настроить в любом другом дистрибутиве.
1) Ставим необходимый софт:
apt-get install obexftp openobex-apps
2) Далее в консоли:
lsusb
на выходе получаем:
Bus 003 Device 003: ID 0421:043a Nokia Mobile Phones
из этого узнаем VendorID и ProductID:
VendorID = 0421
ProductID = 043a
3) Прописываем эти данные в /etc/udev/rules.d/040-permissions.rules:
sudo vim /etc/udev/rules.d/040-permissions.rules
в конец файла вписываем:
BUS=="usb", SYSFS{idVendor}=="VendorID", SYSFS{idProduct}=="ProductID", GROUP="plugdev", USER="yourUserNname"
VendorID и ProductID заменяем нашими данными полученными выводом команды lsusb
USER="имя пользователя под которым вы работаете в системе"
4) Создаём кнопку запуска на рабочем столе. В её свойствах прописываем:
java -jar /home/YOURUSERNAME/obexftp-frontend-0.6.1-bin/OBEXFTPFrontend.jar
YOURUSERNAME меняем на вашу домашнюю папку
5) Запускаем /usr/bin/obexftp
В вкладке Transport выбираем USB, Value 1
Далее OK.
Всё, настройка закончена. Запускаем программу через созданную нами на рабочем
столе кнопку запуска.
В появившемся окошке видим drive c: - это наша memory card. Процесс закачки и
выгрузки файлов понятен интуитивно.
Удачной работы!:)
|
| |
|
|
|
Решение проблемы отсутствия звука в ноутбуках с чипсетом Intel 82801G (доп. ссылка 1) |
Автор: openkazan.info
[комментарии]
|
| | Как ни странно, но в ноутбуках с аудио чипсетом 82801G от Intel (фирмы с
которой обычно нет проблемм)
под линуксом не работает звук. Причём проблемма существует на любых дистрибутивах
(проверено при прочтении форумов с аналогичной проблеммой) и на ноутах самых разных производителей.
ОС на которых мы пытались завести звук: Ubuntu 7.04 Feisty, Ubuntu 7.10 Gutsy, Fedore Core 7.
Ноутбуки на которых люди столкнулись с проблеммой отсутствия звука на 82801G: Acer aspire 5310,
Acer Aspire 3682, Acer TravelMate 2490, Toshiba L40-13G, Sony Vaio SZ110,
Compaq nx7400, IBM Thinkpad Z61m и многие другие...
Во всех системах признаки одни и те же: если звук появляется, то тихий и из
левой колонки слышен пронзительный "свист".
Если переместить ползунок регулировки громкости - звук пропадает совсем.
Данное решение проблеммы описано на модели Toshiba L40-13G
И так,
$lspci |grep Audio
выдаёт нам следующее:
00:1b.0 Audio device: Intel Corporation 82801G (ICH7 Family) High Definition Audio Controller (rev 02)
Решение давольно простое:
В Ubuntu:
$sudo vim /etc/modprobe.d/alsa-base
добавить в конце файла строку
options snd-hda-intel model=3stack
в FedoraCore $sudo vim /etc/modprobe.conf
там где options snd-hda-intel ... в конце строки добавить model=3stack
в других дистрибутивах делать аналогично
далее $sudo update-modules или перезагрузка и должно всё работать:)
|
| |
|
|
|
Выбор и настройка VoIP usb-телефона под linux. (доп. ссылка 1) |
Автор: Сергей Вольхин
[комментарии]
|
| | Выбор.
Меня интересовала не просто работа микрофона и динамика, но и как минимум клавиатуры.
Выбор пал на Skypemate p1K (в девичестве Yealink), как не на очень дорогой апппарат,
при этом имеющий как полноценную клавиатуру ("как у мобильника"), так и простенький ЖК-дисплей.
Ко всему прочему поддержка именно этого девайса в linux наиболее развита.
Настройка.
Поддержка собственно звука не требует практически никакой настройки.
Девайс определяется как новая звуковая карта:
-bash-2.05b# cat /proc/asound/cards
....
USB-Audio - VOIP USB Phone
Yealink Network Technology Ltd. VOIP USB Phone at usb-0000:00:03.0-3
В SIP-клиенте достаточно выбрать например "/dev/dsp2" в качеcтве динамика/микрофона.
Что касается клавиатуры, то с этим ситуация несколько сложней.
Есть несколько проектов разной степени работоспособности:
1. SkypeMate (http://skypemate.ru/support/docs/) - официальный драйвер.
Бинарный, только для FedoraCore 3 (требует старый dbus-0.23).
Плюс ко всему только для Skype. Отдельные джидаи запускали его на современных дистрибутивах
с подменой либы dbus, с периодическими сегфолтами, я с этим заморачиваться не стал.
2. USBB2K-API (http://savannah.nongnu.org/projects/usbb2k-api/) - неофициальный
драйвер. По отзывам пользователей - работает,
однако у меня он не завелся. Девайс определялся, команды на телефон шли,
однако обратной связи не наблюдалось. При этом на форумах отписывали пользователи с аналогичной
проблемой, разработчики пытались им даже помочь, но дело там так и не сдвинулось с мертвой точки.
3. yealink-module (http://savannah.nongnu.org/forum/forum.php?forum_id=4319) -
как видно из названия модуль для ядра.
Последняя версия из CVS у меня собралась лишь после жесткой правки исходников и
после этого кончено нормально не работала, однако релиз за номером 0861 собрался сразу и
без проблем был установлен. Замечу, что поддержка клавиатуры в нем реализована
просто и универсально:
клавиши телефона дублируют клавиши клавиатуры (цифровые, backspace, enter и т.д.)
Оригинал статьи (со ссылками) здесь: http://damnsmallblog.blogspot.com/2007/07/usb-linux.html
|
| |
|
|
|
Установка принтера HP1020 в Debian Еtch |
Автор: Андрей Никитин
[комментарии]
|
| | Принтеры HP LaserJet 1000,1005,1018,1020 после включения должны загрузить
бинарный firmware драйвер.
Если прошивка по каким-то причинам не загружена
(загрузка обычно устанавливается в автомате через hotplug),
то вывод usb_printerid будет примерно таким
nik@linuxdvr:~$ usb_printerid /dev/usb/lp0
GET_DEVICE_ID string:
MFG:Hewlett-Packard;MDL:HP LaserJet 1020;CMD:ACL;CLS:PRINTER;DES:HP LaserJet 1020;
без упоминания версии прошивки в конце строки (FWVER:20041129;)
Устанавливаем штатный deb-пакет foo2zjs
он ставит все что нужно, за исключением самой прошивки
и в логе tail -n 20 /var/log/messages вы увидите что-то подобное
Mar 20 12:35:34 linuxdvr kernel: usbcore: registered new driver usblp
Mar 20 12:35:34 linuxdvr kernel: drivers/usb/class/usblp.c: v0.13: USB Printer Device Class driver
Mar 20 12:35:35 linuxdvr /usr/bin/hplj1020: Missing HP LaserJet 1020 firmware file /usr/share/foo2zjs/firmware/sihp1020.dl
Mar 20 12:35:35 linuxdvr /usr/bin/hplj1020: ...read foo2zjs installation instructions and run ./getweb 1020
Выполняю:
nik@linuxdvr:~$ getweb 1020
в итоге c инета сайта foo2zjs качается прошивка и сохраняется как sihp1020.img
конвертируем этот бинарник в нужный формат
nik@linuxdvr:~$ arm2hpdl sihp1020.img > sihp1020.dl
далее копируем куда нужно
nik@linuxdvr:~$ sudo mv sihp1020.dl /usr/share/foo2zjs/firmware/
и корректируем владельца группу
nik@linuxdvr:~$ sudo chown root:root /usr/share/foo2zjs/firmware/sihp1020.dl
Включаем и выключаем принтер и в логе tail -n 20 /var/log/messages видим
Mar 20 12:57:18 linuxdvr /usr/bin/hplj1020: loading HP LaserJet 1020
firmware /usr/share/foo2zjs/firmware/sihp1020.dl to /dev/usb/lp0 ...
Mar 20 12:57:19 linuxdvr /usr/bin/hplj1020: ... download successful.
Проверяем:
nik@linuxdvr:~$ usb_printerid /dev/usb/lp0
GET_DEVICE_ID string:
MFG:Hewlett-Packard;MDL:HP LaserJet 1020;CMD:ACL;CLS:PRINTER;DES:HP LaserJet 1020;FWVER:20041129;
FWVER:20041129; - это версия успешно загруженной прошивки
Все, теперь идем в KDE, GNOME или ... и запускаем ОТ ROOT-а гуёвые мастера для добавления принтера.
На всякий случай, привожу установленные в Debian Etch пакеты для печати на HP1020 через CUPS.
nik@linuxdvr:~$ aptitude search "foo|cups|foo2" | grep "^i"
i cupsys - Common UNIX Printing System(tm) - server
i cupsys-bsd - Common UNIX Printing System(tm) - BSD comm
i cupsys-client - Common UNIX Printing System(tm) - client p
i A cupsys-common - Common UNIX Printing System(tm) - common f
i cupsys-driver-gutenprint - printer drivers for CUPS
id foo2zjs - Support for printing to ZjStream-based pri
i A foomatic-db - linuxprinting.org printer support - databa
i foomatic-db-engine - linuxprinting.org printer support - progra
i foomatic-db-gutenprint - linuxprinting.org printer support - databa
i foomatic-db-hpijs - linuxprinting.org printer support - databa
i A foomatic-filters - linuxprinting.org printer support - filter
i foomatic-filters-ppds - linuxprinting.org printer support - prebui
i foomatic-gui - GNOME interface for configuring the Foomat
i gnome-cups-manager - CUPS printer admin tool for GNOME
i A libcupsimage2 - Common UNIX Printing System(tm) - image li
i A libcupsys2 - Common UNIX Printing System(tm) - libs
i A libgnomecups1.0-1 - GNOME library for CUPS interaction
i A libgnomecupsui1.0-1c2a - UI extensions to libgnomecups
i A python-foomatic - Python interface to the Foomatic printer d
(С) Андрей Никитин, 2007
Перепечатка и цитирование допускаются только с разрешения автора.
|
| |
|
|
|
Установка CentOS и FC 6 на материнские платы Intel P965 (ICH8R) с IDE-CDROM |
Автор: Державец Борис
[комментарии]
|
| | Установка CentOS 4.4 (RHEL AS 4.4) и FC 6 на материнские платы с чипсетом
Intel P965 & Intel ICH8R с IDE-CDROM'a.
1.Установить в BIOS режим AHCI для Intel ICH8R и Jmicron JMB363
2.На подсказке
boot:linux all-generic-ide pci=nommconf
3. Cпецифицировать во время графической установки
Kernel boot options :
all-generic-ide pci=nommconf
При установке GRUB в /boot partition выполнить:
boot:linux all-generic-ide pci=nommconf rescue
...................
# chroot /mnt/sysimage
# df -h
/dev/sdaX ....... /boot
.............................
# dd if=/dev/sdaX of=linux.bin bs=512 count=1
# mcopy linux.bin a:
Такой стиль установки позволяет системам успешно определять
IDE-CDROM не только при установке , но и в рабочем режиме.
|
| |
|
|
|
Новый способ использования NDIS во FreeBSD 5.x и 6.x
(доп. ссылка 1) |
Автор: Kond
[комментарии]
|
| | Все статьи на opennet описывают создание модуля NDIS для FreeBSD старым методом:
ndiscvt -i *.inf -s *.sys -o ndis_driver_data.h
Данный способ уже давно устарел и теперь нужно использовать программу ndisgen.
Например. Имеем файлы из комплекта Windows драйверов:
Fw1130.bin - Network interface firmware.
FwRad16.bin - Radio firmware.
TNET1130.INF - Driver information file.
tnet1130.sys - Driver binary.
Старый способ:
cd /sys/modules/ndis
make depend
make
make install
cd ../if_ndis
ndiscvt -i TNET1130.INF -s tnet1130.sys -f Fw1130.bin -o ndis_driver_data.h
make depend
make
make install
ndiscvt -f FwRad16.bin
cp FwRad16.bin.ko /boot/kernel
kldload FwRad16.bin
kldload if_ndis
Для автоматизации загрузки помещаем в /boot/loader.conf
FwRad16.bin_load="YES"
if_ndis_load="YES"
Новый способ (не требует установки исходных текстов ядра):
ndisgen
... отвечаем на интерактивные вопросы, на выходе получаем tnet1130_sys.ko
cp tnet1130_sys.ko /boot/kernel/
kldload ndis
kldload if_ndis
kldload tnet1130_sys
Для автоматизации загрузки помещаем в /boot/loader.conf
ndis_load="YES"
if_ndis_load="YES"
tnet1130_sys_load="YES"
|
| |
|
|
|
Как в Linux решить проблему конфликта тачпада и мыши на ноутбуке (доп. ссылка 1) |
Автор: rmcgowan
[комментарии]
|
| | Некоторые проблемы совместной работы мыши и Touchpad можно решить,
добавив параметр загрузки ядра:
psmouse.proto=imps
Ниже пример настройки Touchpad и внешней мыши для X.Org:
# Тачпад
Section "InputDevice"
Driver "synaptics"
Identifier "Mouse2"
Option "Device" "/dev/psaux"
Option "Edges" "1900 5400 1800 3900"
Option "Finger" "25 30"
Option "MaxTapTime" "20"
Option "MaxTapMove" "220"
Option "VertScrollDelta" "100"
Option "MinSpeed" "0.02"
Option "MaxSpeed" "0.18"
Option "AccelFactor" "0.0010"
EndSection
# USB мышь
Section "InputDevice"
Identifier "Mouse1"
Driver "mouse"
Option "Protocol" "IMPS/2"
Option "Device" "/dev/input/mice"
Option "ZAxisMapping" "4 5"
Option "Buttons" "5"
EndSection
Section "ServerLayout"
....
InputDevice "Mouse2" "CorePointer"
InputDevice "Mouse1" "SendCoreEvents"
EndSection
|
| |
|
|
|
Засыпание ноутбука с сохранением данных в памяти (Suspend to RAM) (доп. ссылка 1) (доп. ссылка 2) |
[обсудить]
|
| | cat /proc/acpi/sleep
S0 S3 S4 S4bios S5
Первым делом попробовать:
echo 4b > /proc/acpi/sleep
Если не получилось, ядро нужно грузить с параметрами "noapic acpi_sleep=s3_bios"
Далее если в ядро входят патчи swsusp
(/dev/hda5 - swap раздел, который должен быть раза в два больше ОЗУ):
append=" resume=/dev/hda5"
или для swsusp2: append=" resume2=swap:/dev/hda5"
Если swsusp перестал вообще грузить систему,
используйте параметр ядра "noresume" для игнорирования resume образа.
# Сохраняем статус видеокарты (http://www.srcf.ucam.org/~mjg59/vbetool/)
vbetool vbestate save > ~/VBESTATE
# Засыпаем.
echo 3 > /proc/acpi/sleep
# Восстанавливаем статус видеокарты после просыпания.
vbetool post
vbetool vbestate restore < ~/VBESTATE
Другой вариант засыпания:
echo "mem" >> /sys/power/state
echo "disk" >> /sys/power/state
После просыпания лучше перезапустить hotplug:
service hotplug restart
Еще лучше до засыпания остановить, а после просыпания загрузить сервисы:
usb acpid sound irda pcmcia
Можно скачать готовый скрипт hibernate с http://www.suspend2.net/downloads/all/
Для засыпания по закрытию крышки, создаем /etc/acpi/events/lid
event=button[ /]lid.*
action=echo "3" > /proc/acpi/sleep
При нажатии на кнопку питания, создаем /etc/acpi/events/powerbtn
event=button[ /]power.*
action=echo "3" > /proc/acpi/sleep
Советы по экономии батареи для ноутбуков на базе Pentium Mobile Centrino:
http://wiki.teuwen.org/DebianLaptop
|
| |
|
|
|
Подключение Bluetooth гарнитуры в Fedora Core Linux 4 (доп. ссылка 1) |
Автор: John G. Moylan
[комментарии]
|
| | Устанавливаем поддержку bluetooth (проект Bluez):
yum install bluez-libs bluez-pin bluez-utils bluez-hcidump bluez-utils-cup
Устанавливаем утилиты звуковой подсистемы ALSA:
yum install alsa-tools alsa-lib alsa-utils alsa-lib-devel
Устанавливаем automake (понадобится для сборки BTSCO)
yum install automake
Проверяем на сайте http://bluetooth-alsa.sourceforge.net/ поддерживается ли
наша гарнитура (Jabra BT200 поддерживается).
Запускам hcitool и смотрим активна ли bluetooth подсистема.
Подключаем гарнитуру и запускаем "hcitool scan", смотрим MAC адрес в результатах вывода.
Далее, подключаем через:
hcitool cc MAC
Все должно работать, но на случай проблем, пример некоторый файлов из /etc/bluetooth:
hcid.conf
options {
autoinit yes;
security user;
pairing multi;
# PIN helper
pin_helper /etc/bluetooth/feed-pin.sh;
# D-Bus PIN helper
#dbus_pin_helper;
}
device {
name "%h-%d";
# Local device class
class 0x120104;
# Inquiry and Page scan
iscan enable; pscan enable;
lm accept;
lp rswitch,hold,sniff,park;
# Authentication and Encryption (Security Mode 3)
auth enable;
encrypt enable;
}
rfcomm.conf
rfcomm0 {
# Automatically bind the device at startup
bind no;
# Bluetooth address of the device
device 11:11:11:11:11:11;
# RFCOMM channel for the connection
channel 1;
# Description of the connection
comment "Bluetooth Device
}
/etc/bluetooth/feed-pin.sh
#!/bin/sh
echo "PIN:0000"
Установка BTSCO из исходных текстов.
Получаем исходные тексты из CVS:
cvs -d:pserver:anonymous@cvs.sf.net:/cvsroot/bluetooth-alsa log
cvs -d:pserver:anonymous@cvs.sf.net:/cvsroot/bluetooth-alsa co btsco
Собираем утилиты:
./bootstrap
./configure
make
make install
make maintainer-clean
Собираем модуль ядра:
cd kernel
make
make install
depmod -e
make clean
Подгружаем модуль ядра:
modprobe snd-bt-sco
Подключаемся к гарнитуре:
btsco -v MAC
Небольшой скрипт для автоматизации запуска skype:
#!/bin/sh
modprobe modprobe snd-bt-sco
btsco MACofHeadset
skype
|
| |
|
|
|
Монтирование в Linux флеш-карт, отформатированных цифровой фотокамерой |
Автор: Гусев Андрей
[комментарии]
|
| | После удачно завершившейся разборки с "multiple LUN support" для доступа к девайсам карт-ридеров
(MAUSB-300 производства OLYMPUS и безымянный "11 in 1" Тайваньского производства) оказалось,
что карты xd-Picture (OLYMPUS) и SD (Transcedent), отформатированные в соответствующих аппаратах
(фотокамера CAMEDIA C55ZOOM, и наладонник PalmOne Tungsten E2) монтироваться всё-таки не хотят.
По выяснении обстоятельств оказалось что монтировать их нужно с указанием параметра offset:
xd 16Mb - 20992 (0x5200)
xd 128Mb - 24064 (0x5E00)
xd 256Mb - 25088 (0x6200)
sd 128Mb - 49664 (0xC200)
sd 256Mb - 51712 (0xCA00)
т.е., например, вот так:
> mount -t vfat -o loop,offset=20992 /dev/sda /mnt/ttt
После модификации содержимого карт (добавления/удаления файлов),
смонтированных таким образом соответствующие аппараты не высказывают к этому самому содержимому
(и к файловой системе карт) никаких претензий, т.е. читают его и понимают правильно.
|
| |
|
|
|
Как настроить параметры ISA карты под FreeBSD и Linux |
[комментарии]
|
| | FreeBSD:
/boot/kernel.conf (для карты на 0x300 порту, прерывание 10, IO адрес 0xd8000):
en ed0
po ed0 0x300
ir ed0 10
iom ed0 0xd8000
f ed0 0
q
Linux:
modprobe 3c501 io=0x300 irq=10
или в /etc/modules.conf
alias eth0 3c501
options 3c501 io=0x300 irq=10
Если карта PNP (пакет isapnptools), параметры смотрим через pnpdump и помещаем в /etc/isapnp.conf.
|
| |
|
|
|
Как протестировать целостность ОЗУ не останавливая машину на memtest (доп. ссылка 1) |
Автор: poige
[комментарии]
|
| | получим кучу несжимаемых данных
dd if=/dev/urandom of=random.dat bs=1M count=БОЛЬШЕРАЗМЕРАОЗУ
bzip2 -c < random.dat > random2.dat.bz2
распакуем в /dev/null (можно и на диск конечно)
bzip2 -dc < random2.dat.bz2 > /dev/null
Сбой обычно выглядит так:
bzcat: Data integrity error when decompressing.
|
| |
|
|
|
Настройка WebCam на чипе OV511/OV511+ под FreeBSD (доп. ссылка 1) |
Автор: denz
[комментарии]
|
| |
#!/bin/sh
# Scriptec greb webcam
cur_date=`date \+\%d.\%m.\%Y`
cur_time=`date \+\%H:\%M`
cam_dir=/home/virtual/denz/htdocs/cam
/usr/local/bin/vid -d /dev/ugen0 --small | pnmtojpeg --quality=72 --optimize --smooth 10 \
--progressive --comment="TiraNET Office (67700, Ukraine, Belgorod-Dnestrovsky, P/O Box 4) "\
> /tmp/webcam_shot.jpg
rm -f ${cam_dir}/camout.jpg
/usr/local/bin/convert -normalize -fill white -font helvetica -antialias \
-draw "text 45,230 'WebCam in kladovka [ $cur_time @ $cur_date ]'" \
/tmp/webcam_shot.jpg ${cam_dir}/camout.jpg
rm -f /tmp/webcam_shot.jpg
chown -R denz:www ${cam_dir}/*
|
| |
|
|
|
Синхронизация Smartphone Motorola MPx200 под Linux (доп. ссылка 1) |
[комментарии]
|
| | Есть два способа как заставить MPX200 работать с Linux: IrDA и wince-usb.
1. Подключение через IrDA (SIR):
Устанавливаем параметры для SiR порта
/bin/setserial /dev/ttyS1 port 0x6f8 irq 3 uart 8250 baud_base 115200
irattach /dev/ttyS1 -s
Для RedHat-based Linux дистрибутивов делаем проще:
В /etc/sysconfig/irda
IRDA=yes
DEVICE=/dev/ttyS1
DISCOVERY=yes
# service irda start
Запускем демон синхронизации (не из под root). Качаем с http://synce.sourceforge.net
$ dccm
Если используется пароль запускаем как "dccm -p пароль"
Один раз указываем используемый порт.
# synce-serial-config ircomm0
Стартуем pppd (про hotplug, ниже)
# synce-serial-start
Проверяем.
$ pstatus
Version
=======
Version: 4.20.0 (Microsoft Windows Mobile 2003 for Pocket PC Phone Edition (?))
Platform: 3 (Windows CE)
.....
Завершаем сеанс
# synce-serial-abort
2. Подключение по USB. Для 2.4.x ядра используем user space драйвер wince-usb
http://cvs.sourceforge.net/viewcvs.py/synce/wince-usb/ + http://libusb.sourceforge.net
(последние 2.6.x ядра должны работать с модулями ipaq и usb-serial из коробки).
Патчим. В самом начале ipaqd.c меняем значения IPAQ_ENDPOINT на
#define IPAQ_ENDPOINT_IN 0x82
#define IPAQ_ENDPOINT_OUT 0x02
Далее в devlist[] добавляем
{ 0x045e, 0x00ce, "Motorola MPX200" },
Создаем /usr/local/bin/cebox.sh взяв пример из README к wince-usb, например:
#!/bin/sh
/usr/sbin/pppd nocrtscts local debug passive silent 192.168.1.1:192.168.1.2 ms-dns 192.168.1.1 noauth proxyarp
$ dccm
Подключаем телефон и сразу запускаем
# rmmod ipaq (пока не поправили hotplug)
# ipaqd 2>/var/log/ipaqd.log
Далее запускаем synce-serial-* как в предыдущем шаге.
3. Настройка HotPlug (чтобы все запускалось автоматически).
В /etc/hotplug/usb.agent добавляем после блока с "LABEL="USB product $PRODUCT":
if [ "$PRODUCT" = "45e/ce/0" ]; then
/etc/hotplug/usb/ipaq
exit 0
fi
Создаем /etc/hotplug/usb/ipaq
#!/bin/bash
killall -9 ipaqd
killall dccm
su -c /usr/bin/dccm /user/
/usr/local/bin/ipaqd 2>/var/log/ipaq.log
4. Стандартные команды synce:
pcp - копирование файлов (аналог cp)
pls - список файлов в директории (аналог ls)
pmkdir - создание директории (аналог mkdir)
pmv - перенос/переименование файлов (аналог mv)
prm - удаление файлов (аналог rm)
prmdir - удаление директорий
prun - запуск программы на устройстве
pstatus - статус устройства
synce-install-cab - установка на устройство .cab файла
orange - позволяет выдрать .cab из .exe инсталлера;
В Modnight Commander удобно использовать VFS понимающую команды
"cd #synce" и "cd #synceroot",
правда модуль раздаваемый на сайте synce у меня не заработал, пришлось его переписать:
ftp://ftp.opennet.ru/pub/sys/shell/synce-mcfs-patched/
Для работы, копируем файлы synce и synceroot в /usr/lib/mc/extfs
К extfs.ini добавляем:
synce
synceroot
Хорошая графическая оболочка для синхронизации календаря и адресной книги -
MultiSync (http://multisync.sourceforge.net/)
|
| |
|
|
|
Как подключить USB Card Reader к Linux |
[обсудить]
|
| | Для работы с многокарточными кардридерами необходимо чтобы ядро было
собрано с опцией CONFIG_SCSI_MULTI_LUN=y или подгрузить модуль mod_scsi
с параметром max_scsi_luns=N, иначе Linux будет воспринимать только
первый слот кардридера.
Проверить можно, например, так:
zcat /proc/config.gz | grep CONFIG_SCSI_MULTI_LUN
Решение 1.
При использовании mod_scsi добавить в /etc/modules.conf:
options scsi_mod max_scsi_luns=4294967295
Решение 2.
Заставить ядро опрашивать больше одного LUN у одного устройства.
cat /proc/scsi/scsi и находим первый LUN нашего кардридера.
Host: scsi1 Channel: 00 Id: 00 Lun: 00
выбор цифр ^ ^ ^
Далее:
echo "scsi add-single-device 1 0 0 1" > /proc/scsi/scsi
echo "scsi add-single-device 1 0 0 2" > /proc/scsi/scsi
echo "scsi add-single-device 1 0 0 3" > /proc/scsi/scsi
...
Для удобства монтирования можно прописать в /etc/fstab:
/dev/sda1 /mnt/smcard auto
user,noauto,noexec,mode=0444,rw,sync,codepage=866,iocharset=koi8-r 0 0
/dev/sdb1 /mnt/cfcard auto
user,noauto,noexec,mode=0444,rw,sync,codepage=866,iocharset=koi8-r 0 0
/dev/sdc1 /mnt/sdcard auto
user,noauto,noexec,mode=0444,rw,sync,codepage=866,iocharset=koi8-r 0 0
/dev/sdd1 /mnt/mscard auto
user,noauto,noexec,mode=0444,rw,sync,codepage=866,iocharset=koi8-r 0 0
PS. Для 2.6.x ядра:
echo 8 > /sys/module/scsi_mod/parameters/max_luns
|
| |
|
|
|
Как не разбирая корпус посмотреть модель материнской платы (доп. ссылка 1) |
Автор: Anton V. Yuzhaninov
[комментарии]
|
| | 1. Просмотреть содержимое BIOS (проверял под Linux и FreeBSD)
dd if=/dev/mem bs=64k skip=15 count=1 | strings | less
в первых строчках обычно упоминается название материнской платы.
2. Воспользоваться утилитой dmidecode
|
| |
|
|
|
Как в Linux посмотреть порт/прерывание для ISA/PCI устройств. |
[обсудить]
|
| | pnpdump -c > isapnp.conf - дамп isa/pnp параметров
isapnp isapnp.conf - установить параметры после изменения isapnp.conf
lspci, lspci -v, lspci -vvv - список pci устройств.
scanpci или lspcidrake - найдет модули Linux ядра соответствующие устройствам
(пакеты libhw-tools и ldetect).
lshw - покажет исчерпывающую информацию о USB и PCI устройствах.
setpci - поменять параметры pci устройства
cat /proc/iomem
cat /proc/ioports
cat /proc/interrupts
|
| |
|
|
|
Управление APC UPS через serial порт. |
[комментарии]
|
| | cu -s 2400 -e -o -h -l /dev/cuaa0 # 2400 Baud, 8 Data Bits, 1 Stop Bit, No Parity
Команды:
Y - переход в командный режим, только после Y будут выполняться остальные команды;
K - выключение UPS через 15-30 сек. (K, задержка 1 сек, К, задержка 1 сек, <CR>);
A, X, U и W - самотестироание;
R - окончание сессии;
L - Напряжение на входе;
O - Напряжение на выходе;
B - Вольтаж батареи;
F - Частота в сети, Hz;
M, N - максимальное и минимальное заргистрированное напряжение в сети;
P - потребление энергии в %;
C - температура.
Когда нет питания UPS шлет '!' каждые 5 секунд, если питание появилось - шлет '$'.
|
| |
|
|
|
Как подключить USB Flash накопитель в FreeBSD (доп. ссылка 1) |
[комментарии]
|
| | man umass
Конфигурация ядра (FreeBSD 4.8 можно не пересобирать):
device usb
device ohci (OR device uhci)
device umass
device scbus
device da
device pass
В логе смотрим подобное сообщение "da0 at umass-sim0 bus 0 target 0 lun 0"
Монтируем:
mount -t msdos /dev/da0s1 /mnt
|
| |
|
|
|
Почему Linux ядро не использует всю память и пишет "Warning only 960MB will be used". |
[комментарии]
|
| | Если добавление в lilo append="mem=1536M" не помогает:
Необходимо пересобрать 2.2.x ядро с опцией CONFIG_2GB=y
Processor type and features -> Maximum Physical Memory -> 2Gb
Если проблема проявляется в ядре 2.4.x - CONFIG_HIGHMEM, CONFIG_HIGHMEM4G или CONFIG_HIGHMEM64G
|
| |
|
|
|
Включение Hyper-Threading scheduler в Linux, для CPU Xeon. (доп. ссылка 1) |
[комментарии]
|
| | Linux поддерживает Hyper-Threading начиная с ядра 2.4.17.
Ядро должно быть собрано как SMP,
При загрузке, передаем параметр acpismp=force (в lilo: append=" acpismp=force")
проверка работы:
cat /proc/cpuinfo, если среди flags есть "ht", то Hyper-Threading активирован.
|
| |
|
|
|
|
|
Как уменьшить нагрев процессора AMD Athlon/Duron под Linux |
[комментарии]
|
| | Активируем ACPI в ядре (при включенном ACPI не будет работать APM):
"general.setup" активируем "acpi subsystem", "acpi bus" и "acpi Processor entry".
Для Via kt133/133a и kx133:
Включить "охлаждение": setpci -v -H1 -s 0:0.0 52=EB
Выключить: setpci -v -H1 -s 0:0.0 52=6B
Для Via kt266/266a:
Включить: setpci -v -H1 -s 0:0.0 92=EB
Выключить: setpci -v -H1 -s 0:0.0 92=6B
|
| |
|
|
|
Как исправить падения Linux на AMD Athlon/Duron + AGP ? |
[обсудить]
|
| | В /etc/lilo.conf необходимо добавить append="mem=nopentium", например:
image=/boot/vmlinuz
label=linux
root=/dev/hda1
append="mem=nopentium console=tty12 hdc=ide-scsi"
|
| |
|
|
|
Как на сервере обеспечить подключение PS/2 клавиатуры, без перезагрузки |
[комментарии]
|
| | Для того чтобы на загруженный без PS/2 клавиатуры сервер, можно было в любой
момент подключить клавиатуру
без перезагрузки, нужно в конфигурации ядра заменить строку:
device atkbd0 at atkbdc? irq 1 flags 0x1
на
device atkbd0 at atkbdc? irq 1
Т.е. убрать 'flags 0x1' и тем самым разрешить загружать драйвер клавиатуры
при отключенной в момент загрузки клавиатуре.
|
| |
|
|
|
Как сделать ноутбук с APU AMD гораздо тише и холоднее |
Автор: Artem S. Tashkinov
[комментарии]
|
| | Данная заметка касается владельцев ноутбуков на базе APU AMD поколений Zen
3/4/5 без дискретной видеокарты. Применима ли она к другим - я проверить не могу.
Итак, по пунктам:
1. Уменьшение потребления энергии в idle режиме
1.1 Качаем, собираем и устанавливаем утилиту RyzenAdj. Возможно, она есть в
вашем дистрибутиве из коробки - проверьте сами.
1.2 Добавляем в автозапуск системы (rc.local/systemd unit - как вам нравится) следующую команду:
ryzenadj --power-saving
1.3 Возможно (по крайней мере это касается ноутбуков на основе Zen 4), эту
команду нужно запускать после каждого цикла suspend resume и при отключении
подключении питания, ибо EC материнской платы сбрасывает состояние
энергосбережения в обоих случаях.
Данная команда очень немного уменьшает производительность, но вы это не
заметите. На моём HP ноутбуке с Ryzen 7 7840HS энергопотребление в режиме
простоя после использования команды падает с ~3.5W до 0.7W.
2. Уменьшение потребления энергии на задачи, которые не требуют максимальной
производительности процессора.
К сожалению, новомодный amd-pstate совершенно невменяем касаемо частот, которые
он выставляет для задач, не требующих максимальной производительности процессора.
Например, просмотр видео с использование аппаратного ускорения заставляет
процессор висеть примерно на близкой к максимальной частоте, при этом
потребление энергии составляет примерно 15 ватт.
Чтобы избежать этого, нужно выполнить следующую команду:
echo balance_performance | sudo tee /sys/devices/system/cpu/cpufreq/*/energy_performance_preference
При её использовании частота падает примерно вдвое, потребление энергии уменьшается примерно до 7W.
Её также можно добавить в автозапуск системы.
3. Уменьшение максимального энергопотребления и температуры APU.
Команда ryzenadj имеет и другие опции:
--tctl-temp=XX - установка максимальной температуры. Если вы хотите увеличить
срок службы термопасты и вентилятора, советую уменьшить её. Для себя я выставил
значение 80.
--stapm-limit=XXXXX - максимальное потребление энергии в милливаттах (1/1000
ватта), т.е. для 20W следует указывать 20000. Если у вас, например, APU с 54W,
можно сделать его гораздо тише, выставив значение в 31W.
--fast-limit=XXXXX - максимальное пиковое **кратковременное** потребление энергии в милливаттах.
--slow-limit=XXXXX - максимальное пиковое **долговременное** потребление энергии в милливаттах.
Во время автономной работы я запускаю следующую команду:
ryzenadj --tctl-temp=70 --power-saving --stapm-limit=15000 --fast-limit=15000 --slow-limit=10000
К слову сказать, RyzenAdj работает и в Windows.
Источник: Artem S. Tashkinov (birdie). Если будут вопросы, оставляйте их здесь.
|
| |
|
|
|
Настройка работы WiMax в Ubuntu Linux 9.04 |
Автор: Вершинин Егор
[комментарии]
|
| | Имеем:
Ubuntu Linux 9.04
Yota WiMax модем Samsung SWC-U200
и большое желание этот модем использовать в Ubuntu :)
Алгоритм:
1) В запущенной Ubuntu запускаем программу gnome-terminal (Приложения \ Стандартные \ Терминал)
2) Переходим в привилегированный режим (становится пользователем root) - выполняем команду:
sudo su
и вводим свой пароль от учетной записи.
3) Скачиваем последнюю версию драйвера MadWiMax следующей командой:
wget http://madwimax.googlecode.com/files/madwimax-0.1.0.tar.gz
Примечание: Для этого нужно активное интернет-подключение.
4) Теперь распаковываем и переходим в созданный каталог:
tar -xf madwimax-0.1.0.tar.gz
cd madwimax-0.1.0/
5) Дальнейший шаг - нужно установить библиотеки libusb1.x (т.к. драйвер madwimax основан на ней):
apt-get install libusb-1.0-0-dev
программа запросит подтверждение своих действий - соглашается
6) Теперь можно скомпилировать и установить драйвер следующими командами:
./configure
make
make install
после установки скопируйте вручную получившийся бинарник madwimax следующей командой:
cp src/madwimax /usr/bin/
7) Далее: Подключаем модем, ждем 10-20 секунд.
8) Запускаем программу madwimax следующей командой:
/usr/bin/madwimax
программа должна написать примерно следующее:
Device found
Claimed interface
Allocated tap interface: wimax0
теперь мы должны набрать команду ifconfig и убедиться, что сетевой интерфейс wimax0 у нас появился.
9) Последний шаг - осталось запустить DHCP-клиент и получить настройки
IP-адреса, шлюза и DNS-сервера:
dhclient
Примечание: Перед выполнение команды dhclient отключите текущее интернет-подключение.
|
| |
|
|
|
Установка ATI Catalyst 8.5 в Ubuntu 8.04 (доп. ссылка 1) |
Автор: Pronix
[комментарии]
|
| | 1. Скачать ati-driver-installer-8-5-x86.x86_64.run
2. В консоли выполнить для синхронизации списка пакетов, доступных в репозиториях:
sudo apt-get update
Затем, установить пакеты, необходимые для сборки модуля ядра из исходных
текстов и создания deb пакета:
sudo apt-get install build-essential fakeroot dh-make debhelper debconf libstdc++5 dkms linux-headers-$(uname -r)
3. В консоли запускаем инсталлятор драйвера в режиме создания пакетов:
sudo sh ati-driver-installer-8-5-x86.x86_64.run --buildpkg Ubuntu/8.04
4. Теперь нужно занести в черный список драйвер fglrx из репозитория Ubuntu, выполняем
sudo gedit /etc/default/linux-restricted-modules-common
и в строке "DISABLED_MODULES" добавляем "fglrx"
получаем строку:
DISABLED_MODULES="fglrx"
сохраняем файл
5. далее в консоли устанавливаем подготовленные пакеты с драйвером:
sudo dpkg -i xorg-driver-fglrx_8.493*.deb fglrx-kernel-source_8.493*.deb fglrx-amdcccle_8.493*.deb
6. Перезагружаем X сервер.
7. проверяем:
$ fglrxinfo
display: :0.0 screen: 0
OpenGL vendor string: ATI Technologies Inc.
OpenGL renderer string: Radeon X1900 Series
OpenGL version string: 2.1.7537 Release
PS: все вышесказанное проверялось на i386 конфигурации с видеокартой X1900,
для amd64 возможны небольшие отличая в установке.
Оригинал: http://pronix.isgreat.org/news.php?item.86.5
|
| |
|
|
|



 Как вариант предложено дополнительно использовать
Как вариант предложено дополнительно использовать 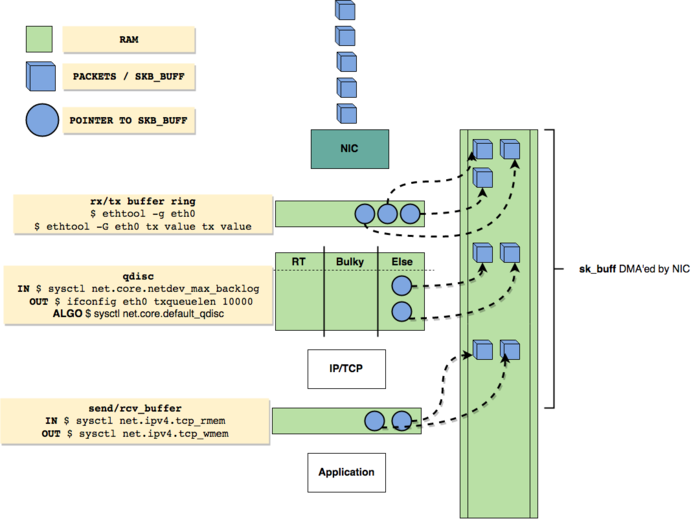 Связь переменных sysctl с различными стадиями обработки сетевых потоков в Linux
Входящие пакеты (Ingress)
1. Пакеты прибывают в NIC (сетевой адаптер)
2. NIC проверяет `MAC` (если не включён promiscuous-режим) и `FCS (Frame check
sequence)` и принимает решение отбросить пакет или продолжить обработку.
3. NIC используя DMA (
Связь переменных sysctl с различными стадиями обработки сетевых потоков в Linux
Входящие пакеты (Ingress)
1. Пакеты прибывают в NIC (сетевой адаптер)
2. NIC проверяет `MAC` (если не включён promiscuous-режим) и `FCS (Frame check
sequence)` и принимает решение отбросить пакет или продолжить обработку.
3. NIC используя DMA ( Источник:
Источник:  Для настройки параметров подключения предоставляется консольный и web-интерфейс
(задаётся пароль подключения к внешней беспроводной сети, пароль для
подключения к ретранслятору и выбор режима работы). Поддерживаются функции
межсетевого экрана, позволяющего ограничить доступ к IP-адресам, подсетям и
сетевым портам через простой ACL, а также ограничить пропускную способность
подключения клиента. Для IoT-устройств предусмотрена поддержка протокола MQTT.
Имеется поддержка режима мониторинга, позволяющего анализировать проходящий
через ретранслятор трафик в приложениях, поддерживающих формат pcap (например, wireshark).
Для прошивки достаточно подключить плату через последовательный порт или
переходник USB2Serial,
Для настройки параметров подключения предоставляется консольный и web-интерфейс
(задаётся пароль подключения к внешней беспроводной сети, пароль для
подключения к ретранслятору и выбор режима работы). Поддерживаются функции
межсетевого экрана, позволяющего ограничить доступ к IP-адресам, подсетям и
сетевым портам через простой ACL, а также ограничить пропускную способность
подключения клиента. Для IoT-устройств предусмотрена поддержка протокола MQTT.
Имеется поддержка режима мониторинга, позволяющего анализировать проходящий
через ретранслятор трафик в приложениях, поддерживающих формат pcap (например, wireshark).
Для прошивки достаточно подключить плату через последовательный порт или
переходник USB2Serial,  Зона покрытия без отражающего экрана:
Зона покрытия без отражающего экрана:
 Зона покрытия с отражающим экраном:
Зона покрытия с отражающим экраном:

 Трафик HTTP и HTTPS, выходящий из облака нашей сети (в примере VLAN90) через
наш бордер CISCO, мы будем сравнивать с ACL, содержащим IP-адреса, извлеченные
из списка Роскомнадзора. В случае совпадения, мы отправляем трафик по протоколу
WCCP (Web Cache Communication Protocol) на сервер(а) SQUID. Данная схема
позволит нам избежать анализа всего трафика и анализировать только тот, который
идет на заявленные IP, что не может не сказаться положительно на общей
производительности системы.
Из минусов данной связки следует, что допустим если внесенный в реестр ресурс с
IP=3.3.3.3, доменом=bad.xxx и URL=
Трафик HTTP и HTTPS, выходящий из облака нашей сети (в примере VLAN90) через
наш бордер CISCO, мы будем сравнивать с ACL, содержащим IP-адреса, извлеченные
из списка Роскомнадзора. В случае совпадения, мы отправляем трафик по протоколу
WCCP (Web Cache Communication Protocol) на сервер(а) SQUID. Данная схема
позволит нам избежать анализа всего трафика и анализировать только тот, который
идет на заявленные IP, что не может не сказаться положительно на общей
производительности системы.
Из минусов данной связки следует, что допустим если внесенный в реестр ресурс с
IP=3.3.3.3, доменом=bad.xxx и URL= Быстрые и неправильные решения
Данные проблемы можно попытаться решить наскоком, и что может ложно успокоить,
"всё будет работать". Поменяв маршрут по умолчанию на белых хостах на
собственный маршрутизатор создастся видимость, что всё починилось:
маршрутизация до филиалов и серых сетей появилась, а межсетевой экран даже
сможет срабатывать на выход. Но кому более всего нужен межсетевой экран на
выход? Вот то-то же. Да и с маршрутизацией не всё на самом деле в порядке.
На каждый посланный вами из белой сети в Интернет пакет, вы будете получать
ICMP redirect, говорящий, что маршрутизатор вами установлен не тот:
PING branch.mydomain.ru (branch-IP): 56 data bytes
From GW-IP Redirect (change route)
84 bytes from branch-IP: icmp_seq=0 ttl=63 time=N ms
Windows машины, у которых по умолчанию применяется политика реагирования на
этот код, будут бесконечно добавлять в таблицу маршрутизации записи на каждый
хост в Интернете через маршрутизатор провайдера.
Хорошо, а давайте добавим все статические маршруты, а между провайдерским и
своим коммутатором поставим прозрачный файервол. Ну что ж, это решение будет
работать пока вам не надоест возиться с маршрутизацией и не возникнет мысль,
что может сделаем управляющий интерфейс прозрачного файервола в белой сети и он
и будет центральным маршрутизатором. Увы, как только вы это сделаете, всё
вернётся к проблеме, описанной ранее.
Правильное решение
Из предыдущей главы стало понятно, что нам нужно:
Быстрые и неправильные решения
Данные проблемы можно попытаться решить наскоком, и что может ложно успокоить,
"всё будет работать". Поменяв маршрут по умолчанию на белых хостах на
собственный маршрутизатор создастся видимость, что всё починилось:
маршрутизация до филиалов и серых сетей появилась, а межсетевой экран даже
сможет срабатывать на выход. Но кому более всего нужен межсетевой экран на
выход? Вот то-то же. Да и с маршрутизацией не всё на самом деле в порядке.
На каждый посланный вами из белой сети в Интернет пакет, вы будете получать
ICMP redirect, говорящий, что маршрутизатор вами установлен не тот:
PING branch.mydomain.ru (branch-IP): 56 data bytes
From GW-IP Redirect (change route)
84 bytes from branch-IP: icmp_seq=0 ttl=63 time=N ms
Windows машины, у которых по умолчанию применяется политика реагирования на
этот код, будут бесконечно добавлять в таблицу маршрутизации записи на каждый
хост в Интернете через маршрутизатор провайдера.
Хорошо, а давайте добавим все статические маршруты, а между провайдерским и
своим коммутатором поставим прозрачный файервол. Ну что ж, это решение будет
работать пока вам не надоест возиться с маршрутизацией и не возникнет мысль,
что может сделаем управляющий интерфейс прозрачного файервола в белой сети и он
и будет центральным маршрутизатором. Увы, как только вы это сделаете, всё
вернётся к проблеме, описанной ранее.
Правильное решение
Из предыдущей главы стало понятно, что нам нужно:

 Мы видим - сервер получил нужные параметры.
Теперь выполним команду:
# ./adc_install.sh -ad_install
Мы видим - сервер получил нужные параметры.
Теперь выполним команду:
# ./adc_install.sh -ad_install
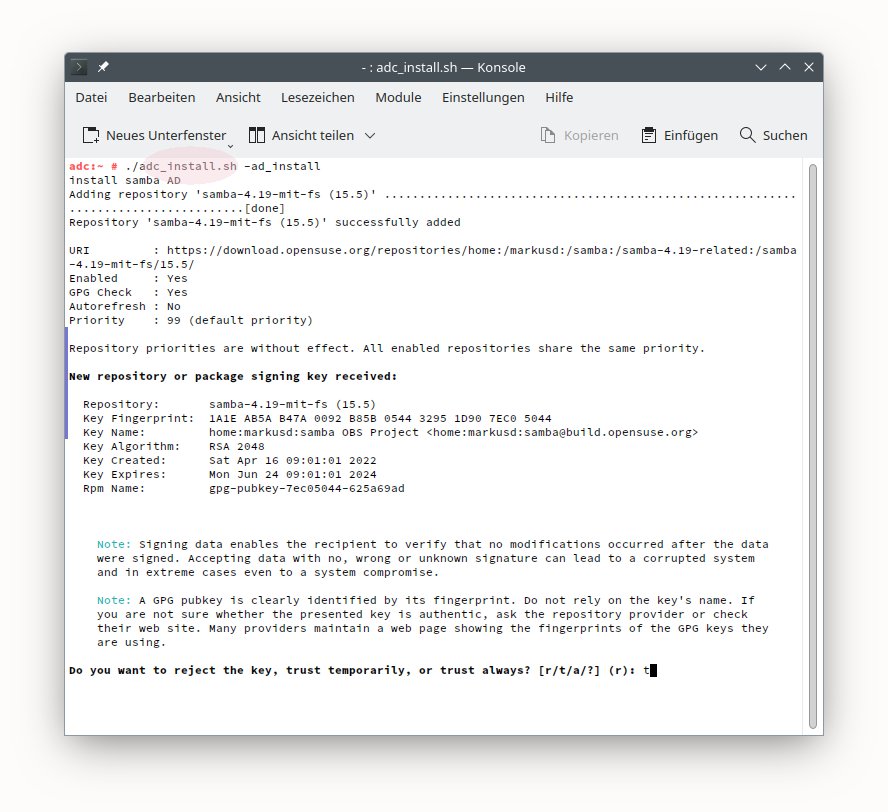 Зададим пароль администратору Samba AD... ну скажем --> "OpenSUSE15".
Зададим IP DNS --> 192.168.1.1
Зададим пароль администратору Samba AD... ну скажем --> "OpenSUSE15".
Зададим IP DNS --> 192.168.1.1
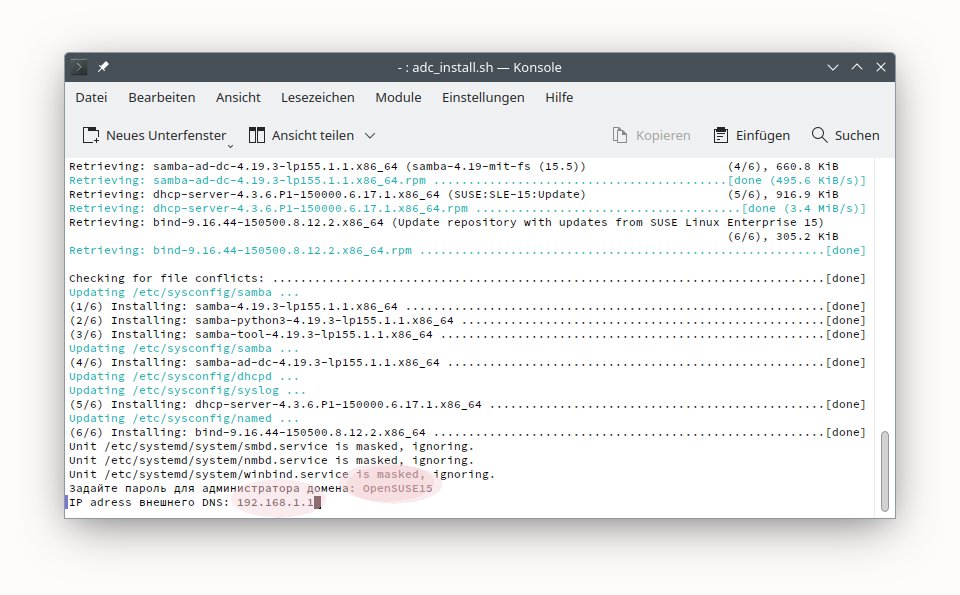
 Установка Samba AD+DDNS+DHCPD закончена.
Осталось только сделать "reboot" сервера, чтобы наши установки вступили в силу.
После старта проверим статус Samba AD, DNS и DHCP-Сервера.
Выполним команду:
# ./adc_install.sh -ad_restart
... и проверим статус сервера выполнив команду:
# ./adc_install.sh -ad_status
Установка Samba AD+DDNS+DHCPD закончена.
Осталось только сделать "reboot" сервера, чтобы наши установки вступили в силу.
После старта проверим статус Samba AD, DNS и DHCP-Сервера.
Выполним команду:
# ./adc_install.sh -ad_restart
... и проверим статус сервера выполнив команду:
# ./adc_install.sh -ad_status
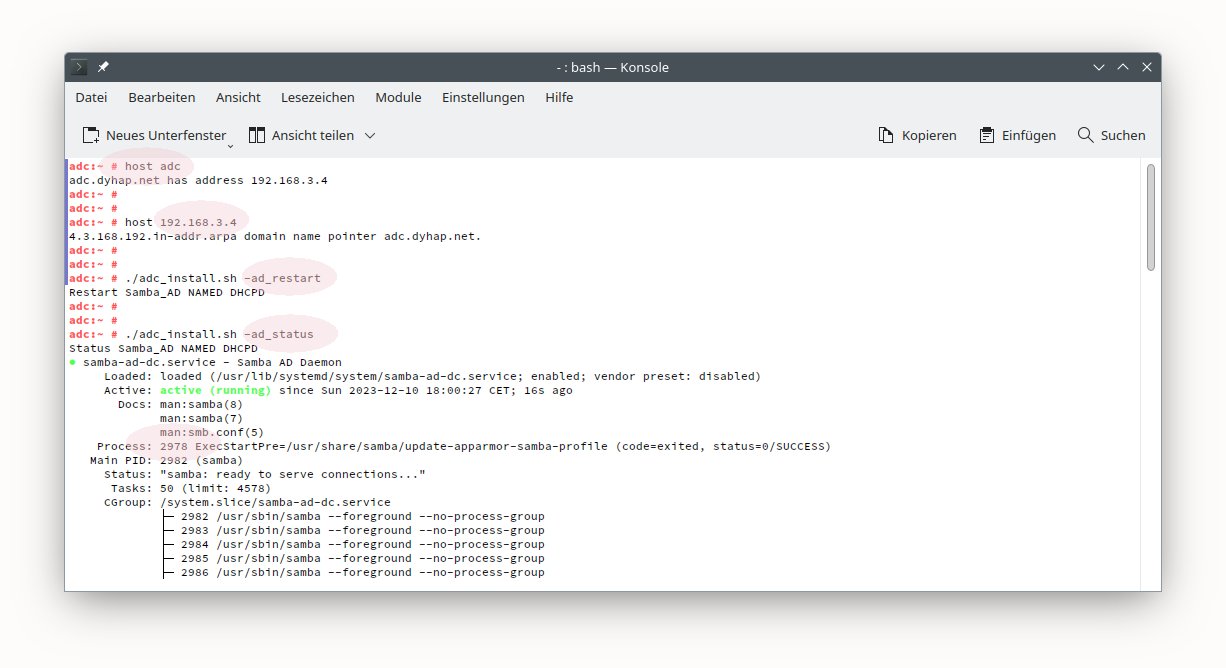
 Сделаем тест системы.
И выполним команду:
# ./adc_install.sh -ad_test
Сделаем тест системы.
И выполним команду:
# ./adc_install.sh -ad_test
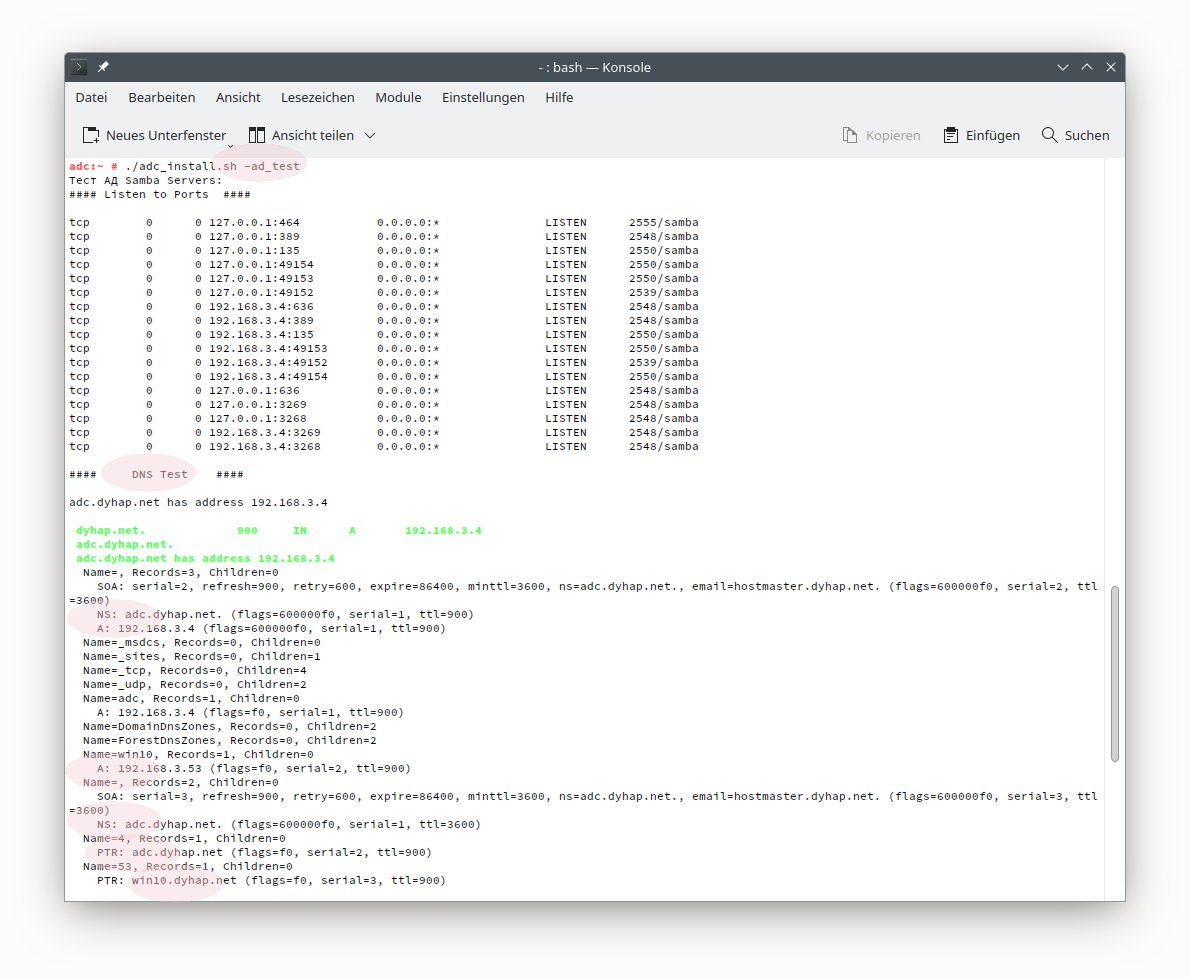
 Теперь можем создать пользователя домена... ну скажем --> Wasja Pupkin.
Выполним команду:
# ./adc_install.sh -uadd
Теперь можем создать пользователя домена... ну скажем --> Wasja Pupkin.
Выполним команду:
# ./adc_install.sh -uadd

 Wasja Pupkin получил login для машины Windows в домене DYHAP: --> w.pupkin
Так же netlogon скрипт: --> w.pupkin.bat
И email-адрес: --> w.pupkin@dyhap.net
Выполним команду:
# ./adc_install.sh -mail_test
А вот email-адреса "test_user@dyhap.net" как и пользователя домена "test_user" в системе нет.
Создадим пользователя домена --> test_user.
Wasja Pupkin получил login для машины Windows в домене DYHAP: --> w.pupkin
Так же netlogon скрипт: --> w.pupkin.bat
И email-адрес: --> w.pupkin@dyhap.net
Выполним команду:
# ./adc_install.sh -mail_test
А вот email-адреса "test_user@dyhap.net" как и пользователя домена "test_user" в системе нет.
Создадим пользователя домена --> test_user.
 Установка Samba Active Directory Domain Controller закончена.
Теперь приступим к установке почтового сервера.
Выполнив команду:
# ./adc_install.sh -mail_inst
мы установим:
1. service postfix
2. service dovecot
3. service amavis
4. service spamd
5. service clamd
6. service clamav-milter
7. service fail2ban
8. service freshclam
Для этого необходимо создать:
1. ssl-сертификаты
2. администратора почтового сервера... --> mailadmin
3. пароль администратору mailadmin .. ну скажем --> "OpenSUSE15"
Установка Samba Active Directory Domain Controller закончена.
Теперь приступим к установке почтового сервера.
Выполнив команду:
# ./adc_install.sh -mail_inst
мы установим:
1. service postfix
2. service dovecot
3. service amavis
4. service spamd
5. service clamd
6. service clamav-milter
7. service fail2ban
8. service freshclam
Для этого необходимо создать:
1. ssl-сертификаты
2. администратора почтового сервера... --> mailadmin
3. пароль администратору mailadmin .. ну скажем --> "OpenSUSE15"
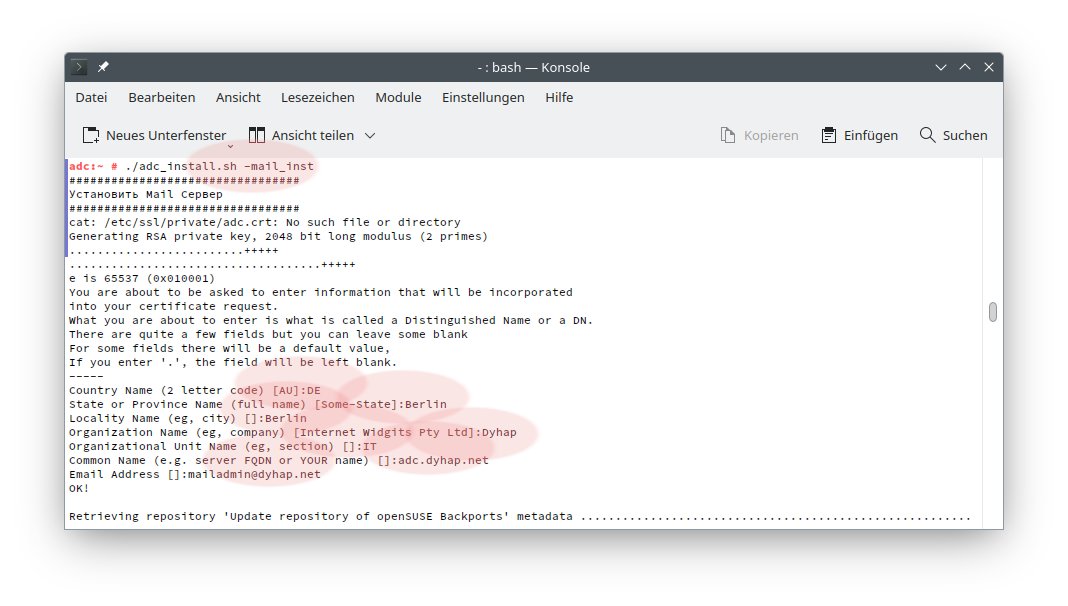

 Установка почтового Сервера закончена.
Теперь можно добавить компьютер Windows по имени "win12" в домен Active Directory.
1. Стартуем компьютер в локальной сети
--> параметры сетевого адаптера получены от DHCP сервера
2. "test_user" в домене --> DYHAP\test_user
3. IP адрес win12.dyhap.net --> 192.168.3.50
4. DHCP-Сервер ввёл win12.dyhap.net в DNS
Установка почтового Сервера закончена.
Теперь можно добавить компьютер Windows по имени "win12" в домен Active Directory.
1. Стартуем компьютер в локальной сети
--> параметры сетевого адаптера получены от DHCP сервера
2. "test_user" в домене --> DYHAP\test_user
3. IP адрес win12.dyhap.net --> 192.168.3.50
4. DHCP-Сервер ввёл win12.dyhap.net в DNS
 Стандартный процесс --> администратор "win12" вводит его в домен.
Стандартный процесс --> администратор "win12" вводит его в домен.
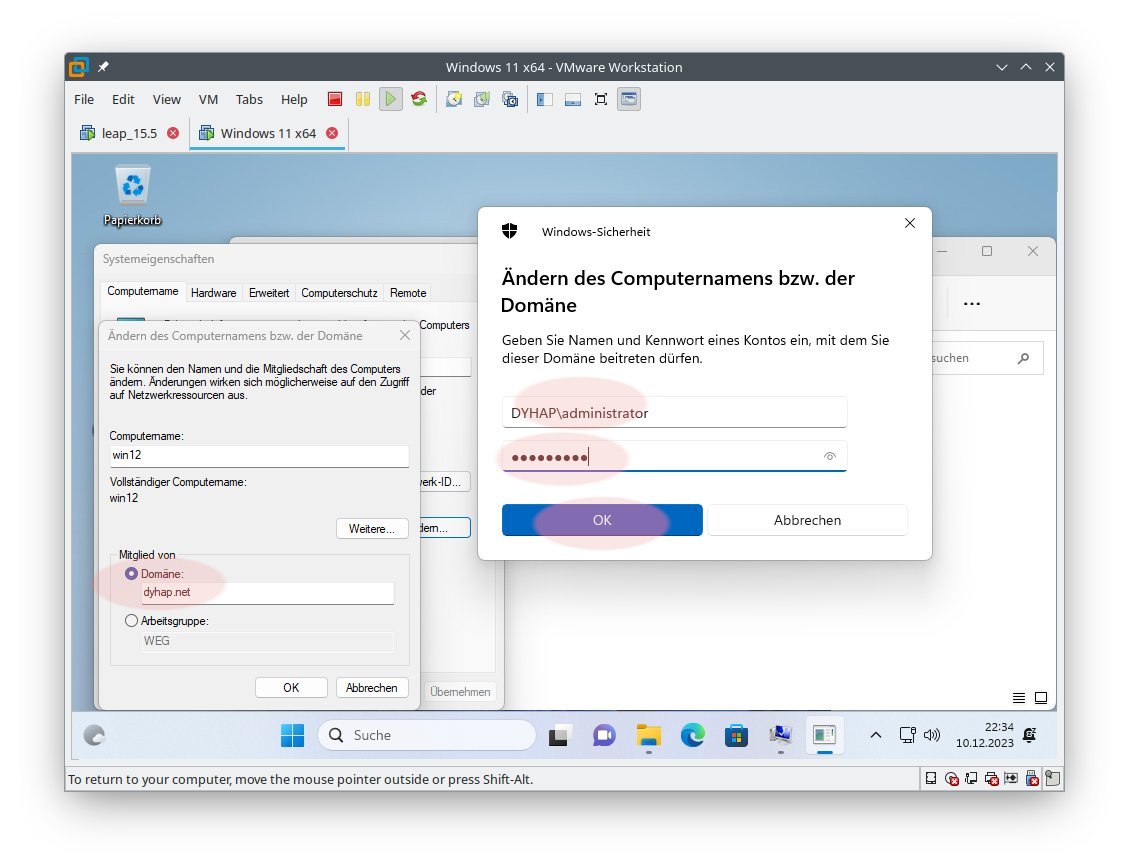
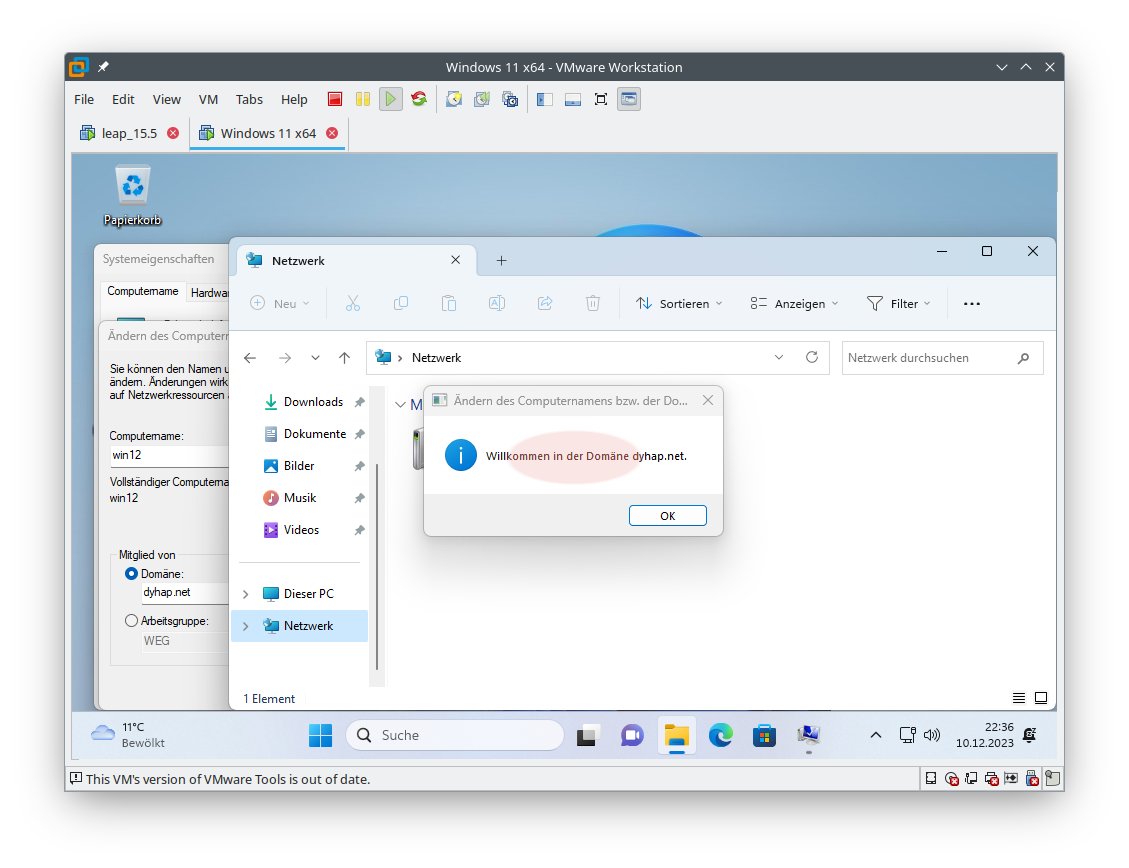

 В окне авторизации test_user указывает свои учетные данные и получает права на
ввод в рабочей станции win12 в домен.
В окне авторизации test_user указывает свои учетные данные и получает права на
ввод в рабочей станции win12 в домен.
 Теперь test_user получил доступ к таким ресурсам в Active Directory,
как электронная почта, приложения и сеть.
При входе стартует скрипт "test_user.bat" и test_user получил доступ
к таким ресурсам "Users" и "public" в сети Active Directory
Теперь test_user получил доступ к таким ресурсам в Active Directory,
как электронная почта, приложения и сеть.
При входе стартует скрипт "test_user.bat" и test_user получил доступ
к таким ресурсам "Users" и "public" в сети Active Directory
 Домашний каталог test_user на сервере.
1. Перемещаемый профиль --> test_user.V6
2. Почтовый каталог --> Maildir
Домашний каталог test_user на сервере.
1. Перемещаемый профиль --> test_user.V6
2. Почтовый каталог --> Maildir

 Теперь протестируем работу почтового Сервера .
Выполним команду:
# ./adc_install.sh -mail_status
Теперь протестируем работу почтового Сервера .
Выполним команду:
# ./adc_install.sh -mail_status

 [[IMG /soft/adc/mail/[33.jpg]]
[[IMG /soft/adc/mail/[33.jpg]]
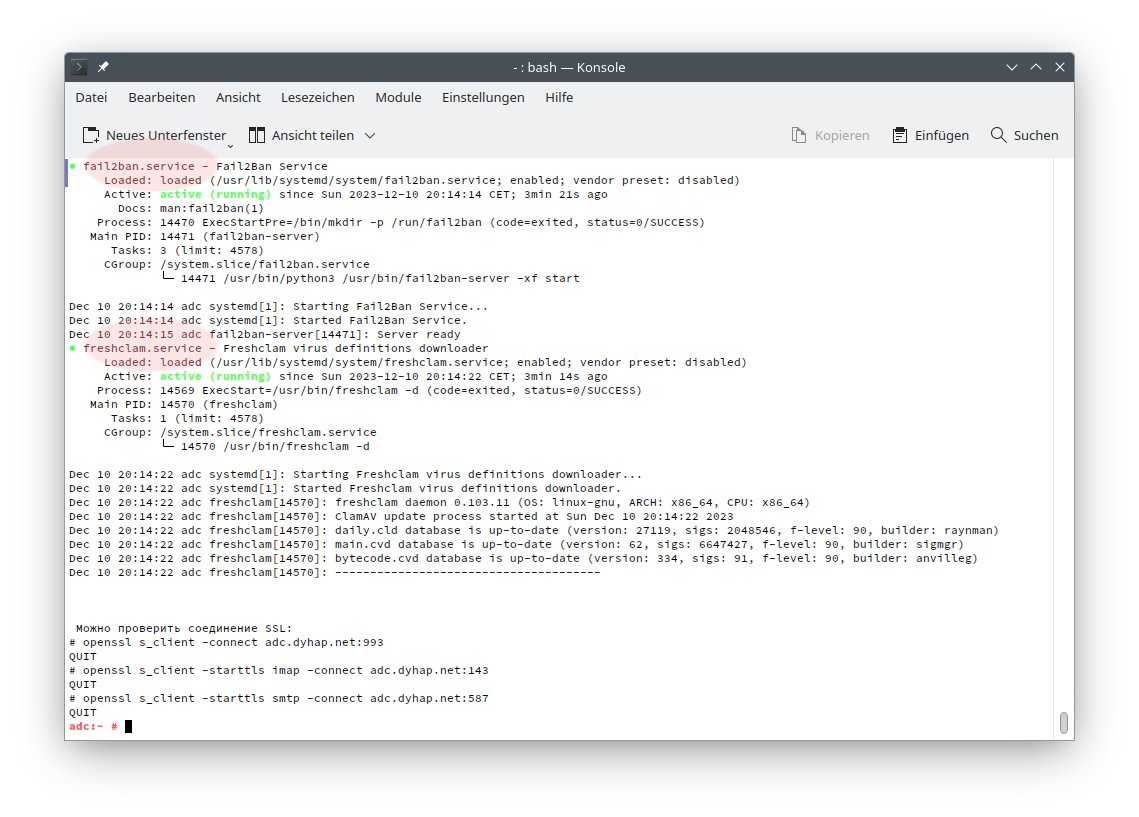 ...всё работает
Стартуем на сервере почтовый клиент Thunderbird.
1. Cоздадим учетную запись почты пользователя --> "mailadmin"
2. "mailadmin" отправил письмо пользователю --> "gennadi@dyhap.net"
3. Сообщение об ошибке можно проигнорировать и повторить
4. Это информация о том, что ssl-сертификаты самодельные.
...всё работает
Стартуем на сервере почтовый клиент Thunderbird.
1. Cоздадим учетную запись почты пользователя --> "mailadmin"
2. "mailadmin" отправил письмо пользователю --> "gennadi@dyhap.net"
3. Сообщение об ошибке можно проигнорировать и повторить
4. Это информация о том, что ssl-сертификаты самодельные.

 Пользователь "gennadi" принимает письмо от "mailadmin" почтовым клиентом KMail openSUSE 15.5 .
Стартуем на сервере почтовый клиент Kmail.
1. Cоздадим учетную запись почты пользователя --> "gennadi"
4. И принимаем информацию о том, что ssl-сертификаты самодельные.
Пользователь "gennadi" принимает письмо от "mailadmin" почтовым клиентом KMail openSUSE 15.5 .
Стартуем на сервере почтовый клиент Kmail.
1. Cоздадим учетную запись почты пользователя --> "gennadi"
4. И принимаем информацию о том, что ssl-сертификаты самодельные.






 Пользователь "gennadi" получил письмо от "mailadmin" и отправляет ответ.
Пользователь "mailadmin" отправляет письмо с тест-вирусом:
X5O!P%@AP[4\PZX54(P^)7CC)7}$EICAR-STANDARD-ANTIVIRUS-TEST-FILE!$H+H*
--> на имя "gennadi". НО антивирус "clamd" заблокировал его.
Пользователь "gennadi" получил письмо от "mailadmin" и отправляет ответ.
Пользователь "mailadmin" отправляет письмо с тест-вирусом:
X5O!P%@AP[4\PZX54(P^)7CC)7}$EICAR-STANDARD-ANTIVIRUS-TEST-FILE!$H+H*
--> на имя "gennadi". НО антивирус "clamd" заблокировал его.

 Пользователь "gennadi" отправляет письмо с ANTI-SPAM-TEST:
XJS*C4JDBQADN1.NSBN3*2IDNEN*GTUBE-STANDARD-ANTI-UBE-TEST-EMAIL*C.34X
--> на имя "mailadmin". НО антиспам "amavis" отправляет его в карантин.
Пользователь "gennadi" отправляет письмо с ANTI-SPAM-TEST:
XJS*C4JDBQADN1.NSBN3*2IDNEN*GTUBE-STANDARD-ANTI-UBE-TEST-EMAIL*C.34X
--> на имя "mailadmin". НО антиспам "amavis" отправляет его в карантин.
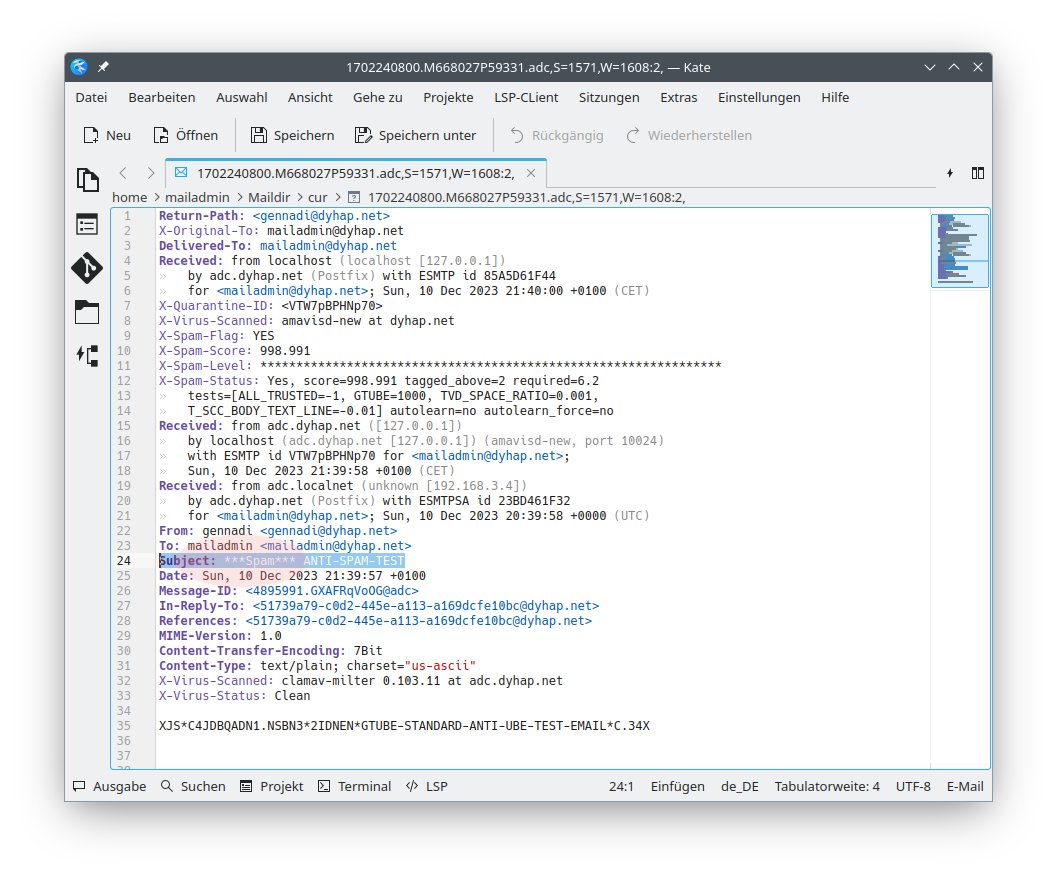
 ANTI-SPAM и ANTIVIRUS работают
Cоздадим учетную запись почты пользователя "test_user" на компьютере "win12"
ANTI-SPAM и ANTIVIRUS работают
Cоздадим учетную запись почты пользователя "test_user" на компьютере "win12"


 Пользователь "test_user" получил письмо от "mailadmin" и отправляет ответ.
Пользователь "test_user" получил письмо от "mailadmin" и отправляет ответ.

 Почтовый Сервер прекрасно работает. НО для работы в интернете нужны настоящие SSL-сертификаты.
Установка Apache2+PHP8+SSL.
Выполним команду:
# ./adc_install.sh -http
Почтовый Сервер прекрасно работает. НО для работы в интернете нужны настоящие SSL-сертификаты.
Установка Apache2+PHP8+SSL.
Выполним команду:
# ./adc_install.sh -http


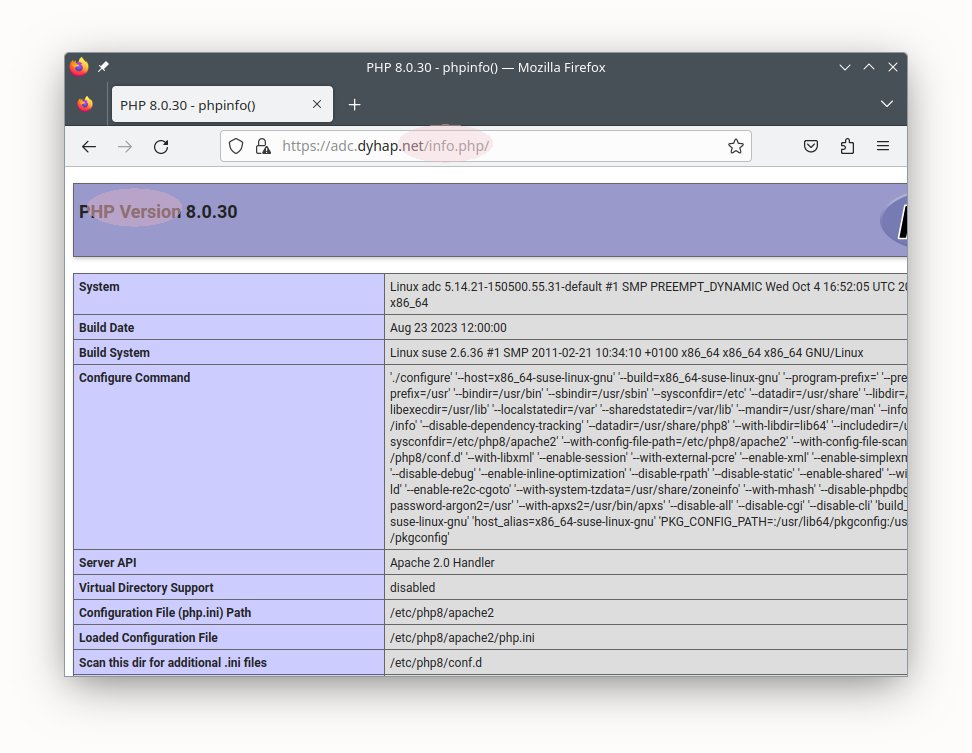 Установка phpMyAdmin.
Выполним команду:
# ./adc_install.sh -madmin
login: root
Password: OpenSUSE15
Установка phpMyAdmin.
Выполним команду:
# ./adc_install.sh -madmin
login: root
Password: OpenSUSE15

 Установка PostfixAdmin.
Выполним команду:
# ./adc_install.sh -padmin
Setup password: OpenSUSE15
Установка PostfixAdmin.
Выполним команду:
# ./adc_install.sh -padmin
Setup password: OpenSUSE15



 Установка Roundcubemail.
Выполним команду:
# ./adc_install.sh -rcube
imap_host = ssl://webmail.dyhap.net:993
smtp_host = ssl://webmail.dyhap.net:465
Любой пользователь домена получает права на пользование Roundcubemail.
Установка Roundcubemail.
Выполним команду:
# ./adc_install.sh -rcube
imap_host = ssl://webmail.dyhap.net:993
smtp_host = ssl://webmail.dyhap.net:465
Любой пользователь домена получает права на пользование Roundcubemail.
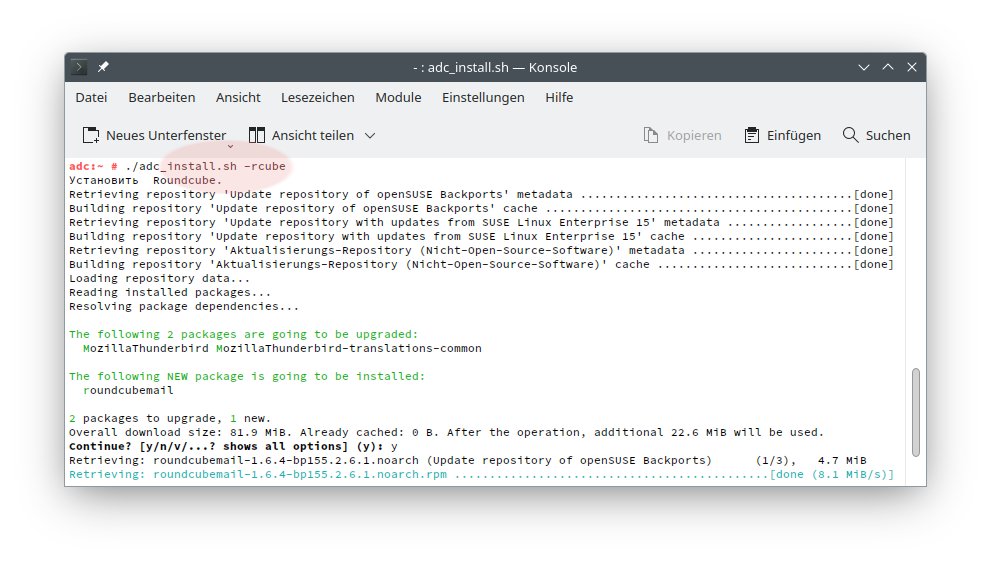


 Установка VSFTPd Сервера.
Выполним команду:
# ./adc_install.sh -ftp
Установка VSFTPd Сервера.
Выполним команду:
# ./adc_install.sh -ftp

 VSFTPd Сервер прекрасно работает.
Пользователь "test_user" получил права на пользование VSFTPd Сервером.
VSFTPd Сервер прекрасно работает.
Пользователь "test_user" получил права на пользование VSFTPd Сервером.


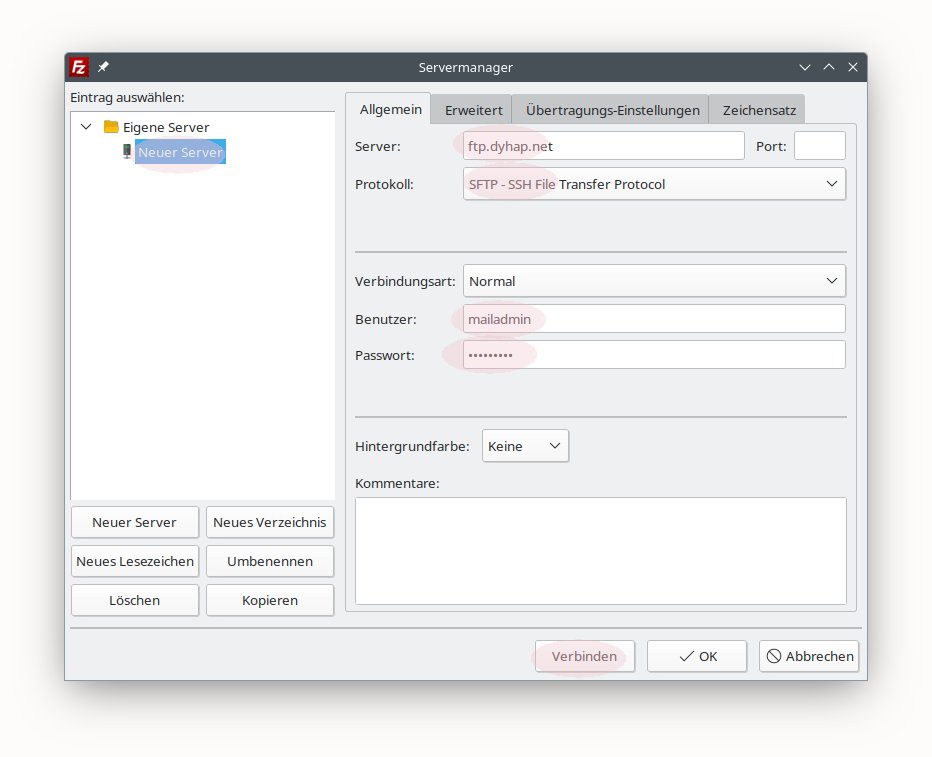
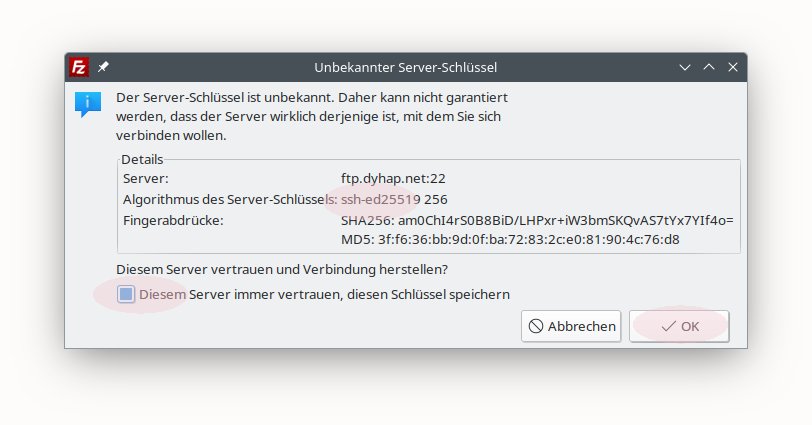

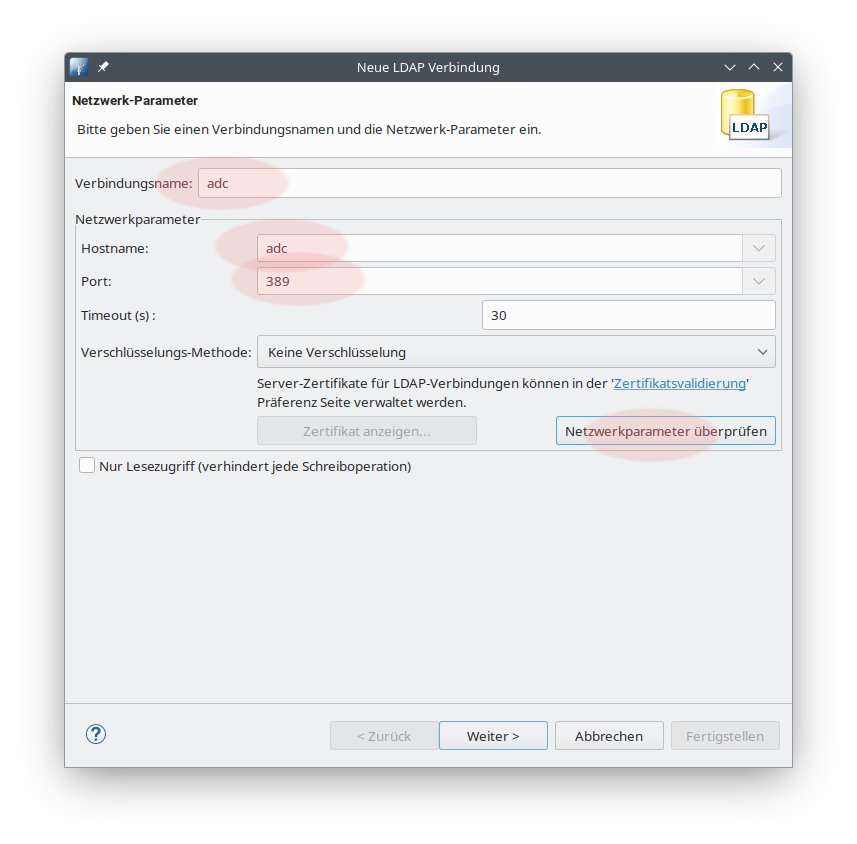
 Это базовая установка Сервера.
Ну вот...и всё, конфигурационные файлы известны и теперь вы можете точнее
настроить сервер под свои нужды.
Уточнение: в статье используются самоподписанные сертификаты, при необходимости
их следует заменить на настоящие SSL-сертификаты.
Это базовая установка Сервера.
Ну вот...и всё, конфигурационные файлы известны и теперь вы можете точнее
настроить сервер под свои нужды.
Уточнение: в статье используются самоподписанные сертификаты, при необходимости
их следует заменить на настоящие SSL-сертификаты.
 Попав в командную строку, начинаем подготовку зеркала. Бегло проглядев вывод
команды dmesg, обнаруживаем, что в связи с новым именованием устройств во
FreeBSD-9.0, в нашем случае диски определились как ada0 и ada1. Ну, раз так,
значит так, создадим из них зеркало gm0 и сразу же загрузим его:
# gmirror label gm0 ada0 ada1
# gmirror load
Теперь в системе появился новый диск - gm0. Убедиться в этом можно посмотрев вывод команды:
# ls -la /dev/mirror/gm0
Однако этот диск пока сырой. Поэтому определим для него схему разбиения на
разделы, в нашем случае - GPT и сделаем этот диск загрузочным:
# gpart create -s gpt mirror/gm0
# gpart bootcode -b /boot/pmbr -p /boot/gptboot -i 1 mirror/gm0
На этом первая часть вмешательства в обычный ход инсталляции FreeBSD может быть
закончена. В самом деле, зачем людям работать руками, если инсталлятор со всем
остальным может справиться самостоятельно? Поэтому смело набираем exit и
выходим из shell'а, чтобы вернуться в инсталлятор, где нам будет предложено
установить имя хоста и выбрать компоненты дистрибутива.
Далее, когда инсталлятор загрузит редактор разделов, наше программное зеркало
будет ему доступно также, как и два физических диска ada0 и ada1. Теперь после
нашего краткого вмешательства, инсталлятор беспрепятственно позволит создать на
зеркале необходимые разделы. Более того все изменения будут даже динамически
отражаться на обеих половинах зеркала:
Попав в командную строку, начинаем подготовку зеркала. Бегло проглядев вывод
команды dmesg, обнаруживаем, что в связи с новым именованием устройств во
FreeBSD-9.0, в нашем случае диски определились как ada0 и ada1. Ну, раз так,
значит так, создадим из них зеркало gm0 и сразу же загрузим его:
# gmirror label gm0 ada0 ada1
# gmirror load
Теперь в системе появился новый диск - gm0. Убедиться в этом можно посмотрев вывод команды:
# ls -la /dev/mirror/gm0
Однако этот диск пока сырой. Поэтому определим для него схему разбиения на
разделы, в нашем случае - GPT и сделаем этот диск загрузочным:
# gpart create -s gpt mirror/gm0
# gpart bootcode -b /boot/pmbr -p /boot/gptboot -i 1 mirror/gm0
На этом первая часть вмешательства в обычный ход инсталляции FreeBSD может быть
закончена. В самом деле, зачем людям работать руками, если инсталлятор со всем
остальным может справиться самостоятельно? Поэтому смело набираем exit и
выходим из shell'а, чтобы вернуться в инсталлятор, где нам будет предложено
установить имя хоста и выбрать компоненты дистрибутива.
Далее, когда инсталлятор загрузит редактор разделов, наше программное зеркало
будет ему доступно также, как и два физических диска ada0 и ada1. Теперь после
нашего краткого вмешательства, инсталлятор беспрепятственно позволит создать на
зеркале необходимые разделы. Более того все изменения будут даже динамически
отражаться на обеих половинах зеркала:
 Далее инсталляция пойдет как по маслу в обычном порядке и до своего логического завершения.
Когда все закончится, перезагружаемся проверить все-ли мы сделали правильно, но
здесь нас поджидает небольшой fail. С прискорбием мы обнаруживаем, что система
загрузиться не может: ядро попросту не понимает, что такое gmirror и не видит зеркала.
Выругавшись нехорошими словами, снова вставляем инсталляционный диск и
загружаемся в так полюбившийся нам shell.
Далее загружаем модуль gmirror и, вспомнив, что корневая файловая система
находится на gm0p3, монтируем корень в /mnt.
# gmirror load
# mount /dev/mirror/gm0p3 /mnt
Теперь остается добавить модуль gmirror в loader.conf для загрузки его вместе с
ядром при старте системы:
# echo ‘geom_mirror_load="YES"’ > /mnt/boot/loader.conf
На этом действительно все. Перезагружаемся и получаем работоспособную систему.
Чтобы убедиться в этом, можно безбоязненно проводить тесты по поочередному
отключению дисков.
Единственный нюанс, внимательный администратор заметит во время загрузки
системы настораживающее предупреждение:
gptboot: invalid backup GPT header
Andrey V. Elsukov - один из разработчиков FreeBSD объясняет это предупреждение так:
"Причина понятна - GPT была создана поверх зеркала. Размер провайдера
mirror/gm0 на 1 сектор меньше, чем размер диска, так как gmirror забирает
последний сектор для хранения своих метаданных. Загрузчик gptboot ничего не
знает о программном зеркале и ищет резервный заголовок GPT в конце диска, а там
находятся метаданные gmirror.
Тут есть небольшое разногласие между gptboot и GEOM_PART_GPT. Некоторое время
назад я изменил алгоритм проверки корректности GPT в GEOM_PART_GPT. А именно,
после прочтения основного заголовка GPT и проверки его контрольной суммы,
резервный заголовок считывается по хранящемуся в основном заголовке адресу. В
случае, когда основной заголовок повреждён, резервный заголовок ищется в конце диска."
Как видим из объяснения разработчика, ничего вроде бы страшного не происходит.
И хотя у нас отсутствует запасной заголовок GPT в конце диска, это не критично,
правда до тех пор, пока все работает.
GPT+gmirror
Этот вариант отличает от предыдущего тем, что зеркалируетяс не диск целиком, а
отдельные его разделы. Как и для первого случая, нам потребуется дистрибутив
FreeBSD-9.0R и два жестких диска, установленных в машину. Как и прежде
рекомендуется, чтобы диски были полностью одинаковыми. Тем не менее, если
случилось так, что один диск больше другого, то инсталляцию FreeBSD лучше
проводить на диск меньшего объема. Это поможет избежать лишних расчетов
размеров разделов при зеркалировании их с большего диска на меньший.
В остальном первоначальная установка FreeBSD-9.0R ничем не отличается от
обычной инсталляции по-умолчанию. Вся настройка зеркалирования начинается, в
тот момент, когда мы загружаем свежепроинсталлированную систему и попадаем в консоль.
Как и в предыдущем случае, диски определились как ada0 и ada1. FreeBSD
установлена на меньший по размеру диск - ada0. Первым делом сохраним
разметку диска и восстановим её на другом диске:
# gpart backup ada0 > ada0.gpt
# gpart restore -F /dev/ada1 < ada0.gpt
# gpart show
Далее инсталляция пойдет как по маслу в обычном порядке и до своего логического завершения.
Когда все закончится, перезагружаемся проверить все-ли мы сделали правильно, но
здесь нас поджидает небольшой fail. С прискорбием мы обнаруживаем, что система
загрузиться не может: ядро попросту не понимает, что такое gmirror и не видит зеркала.
Выругавшись нехорошими словами, снова вставляем инсталляционный диск и
загружаемся в так полюбившийся нам shell.
Далее загружаем модуль gmirror и, вспомнив, что корневая файловая система
находится на gm0p3, монтируем корень в /mnt.
# gmirror load
# mount /dev/mirror/gm0p3 /mnt
Теперь остается добавить модуль gmirror в loader.conf для загрузки его вместе с
ядром при старте системы:
# echo ‘geom_mirror_load="YES"’ > /mnt/boot/loader.conf
На этом действительно все. Перезагружаемся и получаем работоспособную систему.
Чтобы убедиться в этом, можно безбоязненно проводить тесты по поочередному
отключению дисков.
Единственный нюанс, внимательный администратор заметит во время загрузки
системы настораживающее предупреждение:
gptboot: invalid backup GPT header
Andrey V. Elsukov - один из разработчиков FreeBSD объясняет это предупреждение так:
"Причина понятна - GPT была создана поверх зеркала. Размер провайдера
mirror/gm0 на 1 сектор меньше, чем размер диска, так как gmirror забирает
последний сектор для хранения своих метаданных. Загрузчик gptboot ничего не
знает о программном зеркале и ищет резервный заголовок GPT в конце диска, а там
находятся метаданные gmirror.
Тут есть небольшое разногласие между gptboot и GEOM_PART_GPT. Некоторое время
назад я изменил алгоритм проверки корректности GPT в GEOM_PART_GPT. А именно,
после прочтения основного заголовка GPT и проверки его контрольной суммы,
резервный заголовок считывается по хранящемуся в основном заголовке адресу. В
случае, когда основной заголовок повреждён, резервный заголовок ищется в конце диска."
Как видим из объяснения разработчика, ничего вроде бы страшного не происходит.
И хотя у нас отсутствует запасной заголовок GPT в конце диска, это не критично,
правда до тех пор, пока все работает.
GPT+gmirror
Этот вариант отличает от предыдущего тем, что зеркалируетяс не диск целиком, а
отдельные его разделы. Как и для первого случая, нам потребуется дистрибутив
FreeBSD-9.0R и два жестких диска, установленных в машину. Как и прежде
рекомендуется, чтобы диски были полностью одинаковыми. Тем не менее, если
случилось так, что один диск больше другого, то инсталляцию FreeBSD лучше
проводить на диск меньшего объема. Это поможет избежать лишних расчетов
размеров разделов при зеркалировании их с большего диска на меньший.
В остальном первоначальная установка FreeBSD-9.0R ничем не отличается от
обычной инсталляции по-умолчанию. Вся настройка зеркалирования начинается, в
тот момент, когда мы загружаем свежепроинсталлированную систему и попадаем в консоль.
Как и в предыдущем случае, диски определились как ada0 и ada1. FreeBSD
установлена на меньший по размеру диск - ada0. Первым делом сохраним
разметку диска и восстановим её на другом диске:
# gpart backup ada0 > ada0.gpt
# gpart restore -F /dev/ada1 < ada0.gpt
# gpart show
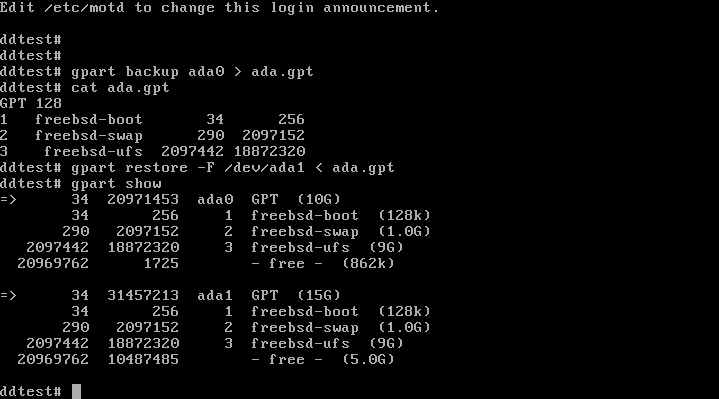 Как видно на скриншоте, разделы удачно скопировались и на бОльшем диске
осталось 5GB свободного неразмеченного места. Теперь по логике вещей, можно
начать зеркалирование разделов.
Однако нужно забыть сделать диск ada1 загрузочным, ведь мы зеркалируем не весь
диск целиком, а только его разделы. Иначе с выходом из строя ada0, система не
сможет загрузится с ada1. Поэтому:
# gpart bootcode -b /boot/pmbr -p /boot/gptboot -i 1 ada1
Кроме того, раздел /dev/da0p3 - содержит корневую файловую систему, он
смонтирован, и размонтировать его не получится, поэтому в текущем положении
изменить его не возможно.
Поэтому перезагружаем систему и загружаемся с инсталляционного диска, где
привычно уже заходим в shell и на каждом разделе диска ada0 создаем зеркало и
загружаем его:
# gmirror label -vb round-robin boot /dev/ada0p1
# gmirror label -vb round-robin swap /dev/ada0p2
# gmirror label -vb round-robin root /dev/ada0p3
# gmirror load
Итого у нас получаютcя 3 зеркала. Сразу же добавляем к зеркалам по их второй половине:
# gmirror insert boot /dev/ada1p1
# gmirror insert swap /dev/ada1p2
# gmirror insert root /dev/ada1p3
Начнется процедура зеркалирования, длительность которой зависит от объема
данных и характеристик жестких дисков. Наблюдать за этим увлекательным
процессом можно при помощи команды:
# gmirror status
А пока дожидаемся окончания этого процесса, чтобы зря не терять времени, можно
не спеша сделать еще 2 полезные вещи. Первая, добавить модуль gmirror в
загрузку ядра:
# mount /dev/mirror/root /mnt
# echo ‘geom_mirror_load="YES"’ > /mnt/boot/loader.conf
И вторая, отредактировать fstab в соответствии с измененными под зеркала именами разделов:
# cat /mnt/etc/fstab
#Device Mountpoint FStype Options Dump Pass#
/dev/mirror/swap none swap sw 0 0
/dev/mirror/root / ufs rw 1 1
На этом все. После окончания синхронизации зеркал, можно перезагрузиться и
устроить системе тест, отключая то один диск, то другой. Только главное не
увлечься и не забыть, что каждый раз, при возвращении диска в RAID, нужно
обязательно дожидаться окончания процесса синхронизации, иначе вы потеряете данные.
Как видно на скриншоте, разделы удачно скопировались и на бОльшем диске
осталось 5GB свободного неразмеченного места. Теперь по логике вещей, можно
начать зеркалирование разделов.
Однако нужно забыть сделать диск ada1 загрузочным, ведь мы зеркалируем не весь
диск целиком, а только его разделы. Иначе с выходом из строя ada0, система не
сможет загрузится с ada1. Поэтому:
# gpart bootcode -b /boot/pmbr -p /boot/gptboot -i 1 ada1
Кроме того, раздел /dev/da0p3 - содержит корневую файловую систему, он
смонтирован, и размонтировать его не получится, поэтому в текущем положении
изменить его не возможно.
Поэтому перезагружаем систему и загружаемся с инсталляционного диска, где
привычно уже заходим в shell и на каждом разделе диска ada0 создаем зеркало и
загружаем его:
# gmirror label -vb round-robin boot /dev/ada0p1
# gmirror label -vb round-robin swap /dev/ada0p2
# gmirror label -vb round-robin root /dev/ada0p3
# gmirror load
Итого у нас получаютcя 3 зеркала. Сразу же добавляем к зеркалам по их второй половине:
# gmirror insert boot /dev/ada1p1
# gmirror insert swap /dev/ada1p2
# gmirror insert root /dev/ada1p3
Начнется процедура зеркалирования, длительность которой зависит от объема
данных и характеристик жестких дисков. Наблюдать за этим увлекательным
процессом можно при помощи команды:
# gmirror status
А пока дожидаемся окончания этого процесса, чтобы зря не терять времени, можно
не спеша сделать еще 2 полезные вещи. Первая, добавить модуль gmirror в
загрузку ядра:
# mount /dev/mirror/root /mnt
# echo ‘geom_mirror_load="YES"’ > /mnt/boot/loader.conf
И вторая, отредактировать fstab в соответствии с измененными под зеркала именами разделов:
# cat /mnt/etc/fstab
#Device Mountpoint FStype Options Dump Pass#
/dev/mirror/swap none swap sw 0 0
/dev/mirror/root / ufs rw 1 1
На этом все. После окончания синхронизации зеркал, можно перезагрузиться и
устроить системе тест, отключая то один диск, то другой. Только главное не
увлечься и не забыть, что каждый раз, при возвращении диска в RAID, нужно
обязательно дожидаться окончания процесса синхронизации, иначе вы потеряете данные.
 (
( (
( (
( (
( Создаем "Graph", который нам нарисует "Item"
Создаем "Graph", который нам нарисует "Item"
 Результат:
Результат:
{kind=link}
{kind=link}
{kind=link}
{kind=link}
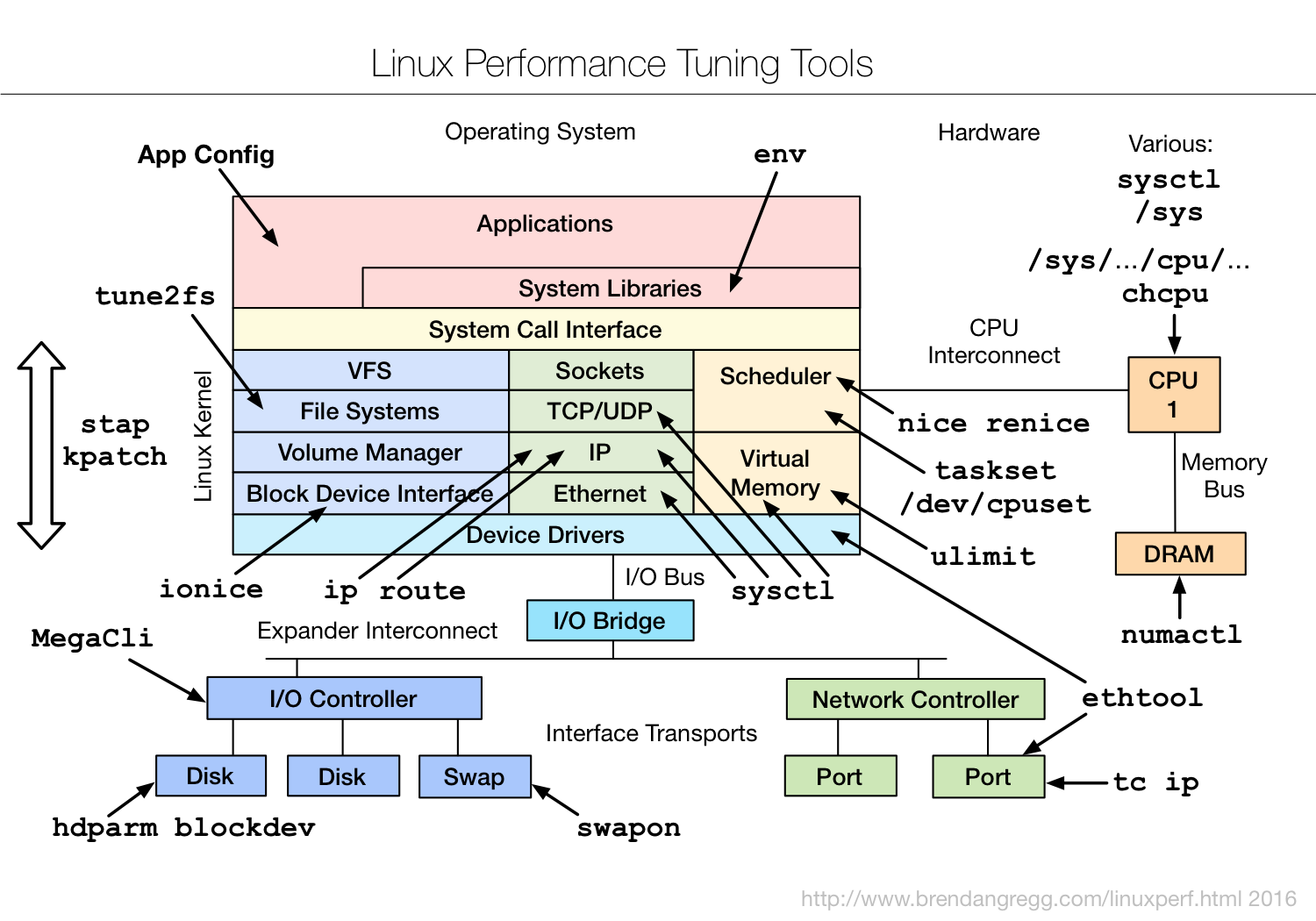{kind=link}
{kind=link}
{kind=link}